COCO128 + Detectron2 + 3LC Tutorial#
This notebook focuses on metrics collection for object detection using the Detectron2 library and the COCO128 subset. No training is performed; instead, we use a pretrained model to evaluate performance. Metrics related to bounding boxes (true positives, false positives, false negatives, iou, confidence) are collected using the BoundingBoxMetricsCollector class.
The notebook illustrates:
Metrics collection on a pretrained Detectron2 model using the COCO128 subset.
Using
BoundingBoxMetricsCollectorfor collecting object detection metrics.Collection per-sample embeddings using
EmbeddingsMetricsCollector
Project Setup#
[2]:
PROJECT_NAME = "COCO128"
RUN_NAME = "COCO128-Metrics-Collection"
DESCRIPTION = "Collect bounding box metrics for COCO128"
TRAIN_DATASET_NAME = "COCO128"
TRANSIENT_DATA_PATH = "../transient_data"
TEST_DATA_PATH = "./data"
MODEL_CONFIG = "COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml"
MAX_DETECTIONS_PER_IMAGE = 30
SCORE_THRESH_TEST = 0.5
TLC_PUBLIC_EXAMPLES_DEVELOPER_MODE = True
INSTALL_DEPENDENCIES = False
[4]:
%%capture
if INSTALL_DEPENDENCIES:
# NOTE: There is no single version of detectron2 that is appropriate for all users and all systems.
# This notebook uses a particular prebuilt version of detectron2 that is only available for
# Linux and for specific versions of torch, torchvision, and CUDA. It may not be appropriate
# for your system. See https://detectron2.readthedocs.io/en/latest/tutorials/install.html for
# instructions on how to install or build a version of detectron2 for your system.
%pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 -f https://download.pytorch.org/whl/cu111/torch_stable.html
%pip install detectron2 -f "https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.10/index.html"
%pip install tlc[pacmap]
%pip install opencv-python
%pip install matplotlib
Imports#
[7]:
tlc: 99.0.0
torch: 1.10 ; cuda: cu111
detectron2: 0.6
[8]:
# Some basic setup:
from __future__ import annotations
# Setup detectron2 logger
from detectron2.utils.logger import setup_logger
logger = setup_logger()
logger.setLevel("ERROR")
# import some common libraries
import random
import cv2
import matplotlib.pyplot as plt
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.utils.visualizer import Visualizer
Prepare the dataset#
A small subset of the COCO dataset (in the COCO standard format) is available in the ./data/coco128 directory.
It is provided while cloning our repository.
Register the dataset with 3LC#
Now that we have the dataset in the COCO format, we can register it with 3LC.
[10]:
from tlc.integration.detectron2 import register_coco_instances
register_coco_instances(
TRAIN_DATASET_NAME,
{},
train_json_path.to_str(),
train_image_folder.to_str(),
project_name=PROJECT_NAME,
)
[11]:
# The detectron2 dataset dicts and dataset metadata can be read from the DatasetCatalog and
# MetadataCatalog, respectively.
dataset_metadata = MetadataCatalog.get(TRAIN_DATASET_NAME)
dataset_dicts = DatasetCatalog.get(TRAIN_DATASET_NAME)
To verify the dataset is in correct format, let’s visualize the annotations of randomly selected samples in the training set:
[12]:
import numpy as np
from detectron2.utils.file_io import PathManager
for d in random.sample(dataset_dicts, 3):
filename = tlc.Url(d["file_name"]).to_absolute().to_str()
if "s3://" in filename:
with PathManager.open(filename, "rb") as f:
img = np.asarray(bytearray(f.read()), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
else:
img = cv2.imread(filename)
visualizer = Visualizer(img[:, :, ::-1], metadata=dataset_metadata, scale=0.5)
out = visualizer.draw_dataset_dict(d)
out_rgb = cv2.cvtColor(out.get_image(), cv2.COLOR_BGR2RGB)
plt.imshow(out_rgb[:, :, ::-1])
plt.title(filename.split("/")[-1])
plt.show()
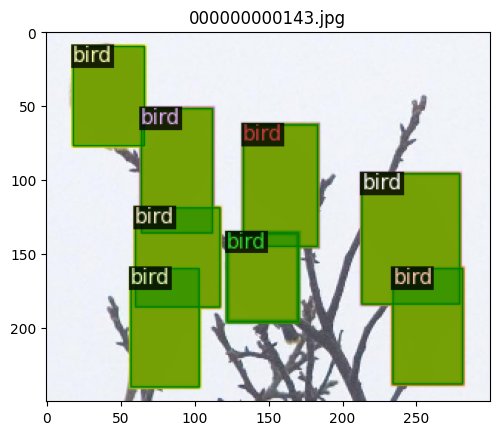

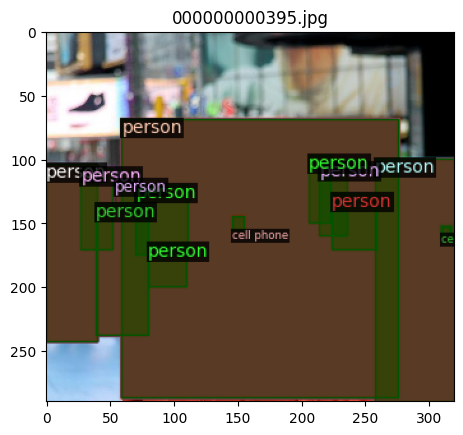
Start a 3LC Run and collect bounding box evaluation metrics#
[13]:
[14]:
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(MODEL_CONFIG))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(MODEL_CONFIG)
cfg.DATASETS.TRAIN = (TRAIN_DATASET_NAME,)
cfg.OUTPUT_DIR = TRANSIENT_DATA_PATH
cfg.DATALOADER.NUM_WORKERS = 0
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 512
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 80
cfg.TEST.DETECTIONS_PER_IMAGE = MAX_DETECTIONS_PER_IMAGE
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = SCORE_THRESH_TEST
cfg.MODEL.DEVICE = "cuda"
cfg.DATALOADER.FILTER_EMPTY_ANNOTATIONS = False
config = {
"model_config": MODEL_CONFIG,
"test.detections_per_image": MAX_DETECTIONS_PER_IMAGE,
"model.roi_heads.score_thresh_test": SCORE_THRESH_TEST,
}
run.set_parameters(config)
[15]:
from tlc.integration.detectron2 import MetricsCollectionHook
from detectron2.engine import DefaultTrainer
trainer = DefaultTrainer(cfg)
# Define Embeddings metrics
layer_index = 138 # Index of the layer to collect embeddings from
embeddings_metrics_collector = tlc.EmbeddingsMetricsCollector(layers=[layer_index])
predictor = tlc.Predictor(trainer.model, layers=[layer_index])
bounding_box_metrics_collector = tlc.BoundingBoxMetricsCollector(
classes=dataset_metadata.thing_classes,
label_mapping=dataset_metadata.thing_dataset_id_to_contiguous_id,
iou_threshold=0.5,
compute_derived_metrics=True,
)
metrics_collection_hook = MetricsCollectionHook(
dataset_name=TRAIN_DATASET_NAME,
metrics_collectors=[bounding_box_metrics_collector, embeddings_metrics_collector],
collect_metrics_before_train=True,
predictor=predictor, # Needs to be used for embeddings metrics
)
trainer.register_hooks([metrics_collection_hook])
trainer.resume_or_load(resume=False)
trainer.before_train()
model_final_b275ba.pkl: 167MB [00:00, 233MB/s]
[16]:
from tlc import Table
val_table = Table.from_url(dataset_metadata.get("latest_tlc_table_url")).url # Get the last revision of the val table
url_mapping = run.reduce_embeddings_by_foreign_table_url(
val_table,
method="pacmap",
n_components=3,
n_neighbors=5,
)