Fine-tuning a Classifier Using Bounding Box Data from a 3LC Table#
This notebook demonstrates how to fine-tune a classifier on cropped bounding box regions. The goal is to aid in the evaluation of larger object detection networks. To achieve this, we implement a custom PyTorch DataLoader based on a single 3LC Table that contains image paths and associated bounding box information.
We utilize a BBCropDataset, a specialized dataset class that ensures balanced sampling of bounding boxes for training. It tracks which bounding boxes have been sampled from each image to guarantee a well-distributed set of training examples.
An optional feature allows the inclusion of a “background” class by sampling image regions devoid of any labeled bounding boxes. This is advantageous for enhancing the model’s ability to discriminate between objects and background.
The dataset supports on-the-fly data augmentation via PyTorch transforms and also provides an option to save cropped images, useful for both visualization and debugging.
The model training employs the timm library for model selection. We pair the BBCropDataset with a RandomWeightedSampler to ensure each image is sampled in proportion to its number of bounding boxes.
Project Setup#
[2]:
PROJECT_NAME = "Bounding Box Classifier"
EPOCHS = 10
TEST_DATA_PATH = "./data"
TRANSIENT_DATA_PATH = "../transient_data"
BATCH_SIZE = 32
DATASET_NAME = "Bounding Box Classification Dataset"
DEVICE = "cuda:0"
TLC_PUBLIC_EXAMPLES_DEVELOPER_MODE = True
INSTALL_DEPENDENCIES = False
[4]:
%%capture
if INSTALL_DEPENDENCIES:
%pip --quiet install torch --index-url https://download.pytorch.org/whl/cu118
%pip --quiet install torchvision --index-url https://download.pytorch.org/whl/cu118
%pip --quiet install timm
%pip --quiet install matplotlib
%pip --quiet install tlc
Imports#
[7]:
from __future__ import annotations
from collections import defaultdict
from io import BytesIO
import random
import os
from PIL import Image
import tqdm.notebook as tqdm
import torch
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import tlc
Set Up Input Table#
[8]:
table_url = tlc.Url.create_table_url(project_name=PROJECT_NAME, dataset_name=DATASET_NAME, table_name="table_from_coco")
annotations_file = tlc.Url(TEST_DATA_PATH + "/balloons/train/train-annotations.json").to_absolute()
images_dir = tlc.Url(TEST_DATA_PATH + "/balloons/train").to_absolute()
input_table = tlc.Table.from_coco(
table_url=table_url,
annotations_file=annotations_file,
image_folder=images_dir,
description="Balloons training dataset from COCO annotations",
if_exists="overwrite",
)
[9]:
# Print the columns of the input table
print(input_table.columns)
['image_id', 'image', 'bbs', 'width', 'height', 'weight']
[10]:
# Get the schema of the bounding box column of the input table
import json
bb_schema = input_table.schema.values["rows"].values["bbs"].values["bb_list"]
label_map = input_table.get_value_map("bbs.bb_list.label")
print(f"Input table uses {len(label_map)} unique labels: {json.dumps(label_map, indent=2)}")
Input table uses 1 unique labels: {
"0.0": {
"internal_name": "balloon",
"display_name": "",
"description": "",
"display_color": "",
"url": ""
}
}
Notice our Table has a “weight” column which could be used for sampling, but since it is all 1’s it is not very useful.
We could however modify the weights in the Dashboard to control the sampling of images.
[11]:
sample_weights_from_weight_column = [row["weight"] for row in input_table.table_rows]
print(sample_weights_from_weight_column)
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
We instead use the number of bounding boxes per image to control sampling.
[12]:
[1, 1, 1, 10, 7, 1, 1, 6, 1, 3, 3, 1, 1, 2, 1, 2, 5, 3, 1, 5, 7, 5, 1, 3, 1, 2, 16, 5, 1, 3, 19, 3, 1, 1, 11, 3, 6, 2, 1, 1, 1, 2, 1, 2, 4, 4, 1, 1, 1, 1, 16, 1, 12, 1, 3, 2, 11, 13, 1, 28, 1]
[13]:
from torch.utils.data import WeightedRandomSampler
sampler = WeightedRandomSampler(sample_weights_from_num_bbs, num_samples=len(input_table))
# Print the first 40 images to be drawn:
print(", ".join([str(next(iter(sampler))) for _ in range(40)]))
4, 52, 23, 56, 50, 36, 34, 3, 30, 50, 34, 38, 26, 21, 10, 17, 52, 26, 41, 59, 27, 49, 20, 13, 56, 57, 50, 55, 59, 59, 59, 21, 16, 16, 29, 21, 56, 34, 59, 6
Define Dataset#
Next, we define our dataset class.
[14]:
class BBCropDataset(Dataset):
def __init__(
self,
table: tlc.Table,
transform=None,
save_images_dir: str = "",
random_seed: int = 42,
is_train: bool = True,
background_freq: float = 0.5,
):
self.table = table
self.bb_schema = table.schema.values["rows"].values["bbs"].values["bb_list"]
self.transform = transform
self.save_images_dir = save_images_dir
self.used_bbs = defaultdict(set)
self.is_train = is_train
self.background_freq = background_freq
self.random_gen = random.Random(random_seed)
self.label_map = table.get_value_map("bbs.bb_list.label")
self.background_label = len(self.label_map)
# Create mappings for contiguous IDs (in case label map is not contiguous)
self.id_to_contiguous = {
original_id: contiguous_id for contiguous_id, original_id in enumerate(self.label_map.keys())
}
self.contiguous_to_id = {
contiguous_id: original_id for original_id, contiguous_id in self.id_to_contiguous.items()
}
self.num_classes = len(self.label_map)
if background_freq > 0:
self.num_classes += 1 # Adding 1 for background class
if self.save_images_dir:
os.makedirs(self.save_images_dir, exist_ok=True)
def __len__(self):
return len(self.table)
def __getitem__(self, idx):
row = self.table.table_rows[idx]
image_filename = row["image"]
image_bbs = row["bbs"]["bb_list"]
if len(image_bbs) == 0:
raise ValueError(f"Image {image_filename} has no bounding boxes. Use a sampler that excludes these images.")
image_bytes = tlc.Url(image_filename).read()
image = Image.open(BytesIO(image_bytes))
w, h = image.size
available_bbs_idxs = list(set(range(len(image_bbs))) - self.used_bbs[idx])
if not available_bbs_idxs:
# print(f"Re-using bbs from sample {idx}")
self.used_bbs[idx] = set()
available_bbs_idxs = list(range(len(image_bbs)))
random_bb_idx = random.choice(available_bbs_idxs)
is_background = False
if self.random_gen.random() < self.background_freq and self.is_train:
is_background = True
gt_boxes = row["bbs"]["bb_list"]
background_patch = self._generate_background(image, gt_boxes, w, h)
crop = background_patch
label = torch.tensor(self.background_label, dtype=torch.int64)
else:
random_bb = image_bbs[random_bb_idx]
self.used_bbs[idx].add(random_bb_idx)
crop = tlc.BBCropInterface.crop(image, random_bb, self.bb_schema, image_height=h, image_width=w)
label = torch.tensor(self.id_to_contiguous[random_bb["label"]], dtype=torch.int64)
if self.save_images_dir:
crop.save(
os.path.join(self.save_images_dir, f"{idx}_{random_bb_idx}{'_background' if is_background else ''}.jpg")
)
if self.transform:
crop = self.transform(crop)
return crop, label
@staticmethod
def _intersects(box1: list[int], box2: list[int]) -> bool:
x1, y1, w1, h1 = box1
x2, y2, w2, h2 = box2
# Check for non-overlapping conditions
if x1 + w1 < x2 or x2 + w2 < x1 or y1 + h1 < y2 or y2 + h2 < y1:
return False
return True
def _generate_background(
self, image: Image.Image, gt_boxes: list, image_width: int, image_height: int
) -> Image.Image:
"""Generate a background patch."""
image_width, image_height = image.size
bb_factory = tlc.BoundingBox.from_schema(self.bb_schema)
gt_boxes_xywh = [
bb_factory([bb["x0"], bb["y0"], bb["x1"], bb["y1"]])
.to_top_left_xywh()
.denormalize(image_width, image_height)
for bb in gt_boxes
]
# Loop until a valid background bounding box is generated
while True:
# Generate proposal box using normal distribution for x, h, w, y
x = max(
min(int(self.random_gen.normalvariate(mu=image_width // 2, sigma=image_width // 6)), image_width - 1), 0
)
y = max(
min(
int(self.random_gen.normalvariate(mu=image_height // 2, sigma=image_height // 6)), image_height - 1
),
0,
)
w = max(
min(int(self.random_gen.normalvariate(mu=image_width // 8, sigma=image_width // 16)), image_width - x),
1,
)
h = max(
min(
int(self.random_gen.normalvariate(mu=image_height // 8, sigma=image_height // 16)), image_height - y
),
1,
)
proposal_box = [x, y, w, h]
if not any(self._intersects(proposal_box, gt_box) for gt_box in gt_boxes_xywh):
break
# Crop the background patch from the image using the proposal_box
background_patch = image.crop((x, y, x + w, y + h))
return background_patch
[15]:
val_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
]
)
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2, hue=0.3),
transforms.RandomRotation(degrees=10),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],
),
]
)
test_dataset = BBCropDataset(input_table, transform=train_transforms)
test_dataloader = DataLoader(test_dataset, batch_size=2, sampler=sampler)
# Read the first 3 batches
num_test_batches = 3
for batch_idx, batch in enumerate(test_dataloader):
images, labels = batch
print(f"Received batch with images of shape {images.shape} and labels of shape {labels.shape}")
if batch_idx == num_test_batches:
break
Received batch with images of shape torch.Size([2, 3, 224, 224]) and labels of shape torch.Size([2])
Received batch with images of shape torch.Size([2, 3, 224, 224]) and labels of shape torch.Size([2])
Received batch with images of shape torch.Size([2, 3, 224, 224]) and labels of shape torch.Size([2])
Received batch with images of shape torch.Size([2, 3, 224, 224]) and labels of shape torch.Size([2])
Train a classifier using the crop dataset#
[16]:
import timm
import torch.nn as nn
import torch.optim as optim
PRINT_FREQUENCY = 1
# Initialize the model
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train_dataset = BBCropDataset(input_table, transform=train_transforms, is_train=True)
train_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, sampler=sampler)
model = timm.create_model("efficientnet_b0", pretrained=True, num_classes=train_dataset.num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9516)
best_accuracy = 0
n_iter = 0
iteration = []
loss_history = []
for epoch in range(EPOCHS):
model.train()
running_loss = 0.0
total = 0
for i, (inputs, labels) in enumerate(tqdm.tqdm(train_dataloader)):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
total += labels.size(0)
n_iter += 1
if n_iter % PRINT_FREQUENCY == 0:
currentloss = 1.0 * running_loss / total
print(f"Iteration: {n_iter}, Loss: {currentloss:.4f}")
iteration.append(n_iter)
loss_history.append(currentloss)
if epoch >= 5:
scheduler.step()
print(f"Epoch [{epoch+1}/{EPOCHS}], Loss: {running_loss / len(train_dataloader):.4f}")
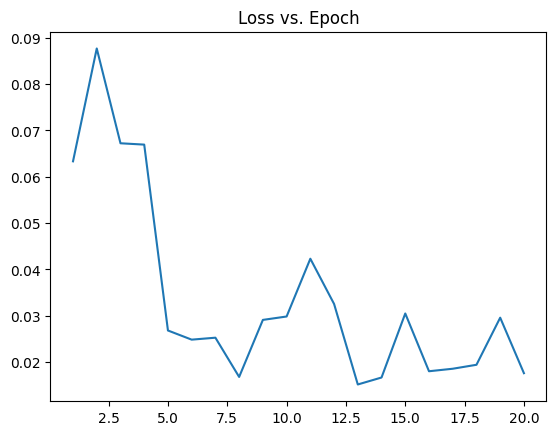
Iteration: 1, Loss: 0.0633
Iteration: 2, Loss: 0.0877
Epoch [1/10], Loss: 2.6742
Iteration: 3, Loss: 0.0672
Iteration: 4, Loss: 0.0669
Epoch [2/10], Loss: 2.0414
Iteration: 5, Loss: 0.0268
Iteration: 6, Loss: 0.0248
Epoch [3/10], Loss: 0.7578
Iteration: 7, Loss: 0.0253
Iteration: 8, Loss: 0.0168
Epoch [4/10], Loss: 0.5124
Iteration: 9, Loss: 0.0291
Iteration: 10, Loss: 0.0298
Epoch [5/10], Loss: 0.9102
Iteration: 11, Loss: 0.0423
Iteration: 12, Loss: 0.0326
Epoch [6/10], Loss: 0.9929
Iteration: 13, Loss: 0.0152
Iteration: 14, Loss: 0.0167
Epoch [7/10], Loss: 0.5086
Iteration: 15, Loss: 0.0305
Iteration: 16, Loss: 0.0180
Epoch [8/10], Loss: 0.5498
Iteration: 17, Loss: 0.0186
Iteration: 18, Loss: 0.0194
Epoch [9/10], Loss: 0.5924
Iteration: 19, Loss: 0.0296
Iteration: 20, Loss: 0.0176
Epoch [10/10], Loss: 0.5370
[17]:
# Save the model to a pth file:
torch.save(model.state_dict(), TRANSIENT_DATA_PATH + "/bb_classifier.pth")
[18]:
import matplotlib.pyplot as plt
plt.plot(iteration, loss_history)
plt.title("Loss vs. Epoch")
plt.show()