Example#
This section explores one possible way to use 3LC with an example - finding and fixing labeling issues in an object detection dataset.
For this example, we have trained an object detection model on the Hard Hat Workers dataset. While 3LC can be used to collect metrics throughout the training process, for this example we have only collected metrics after training has finished.
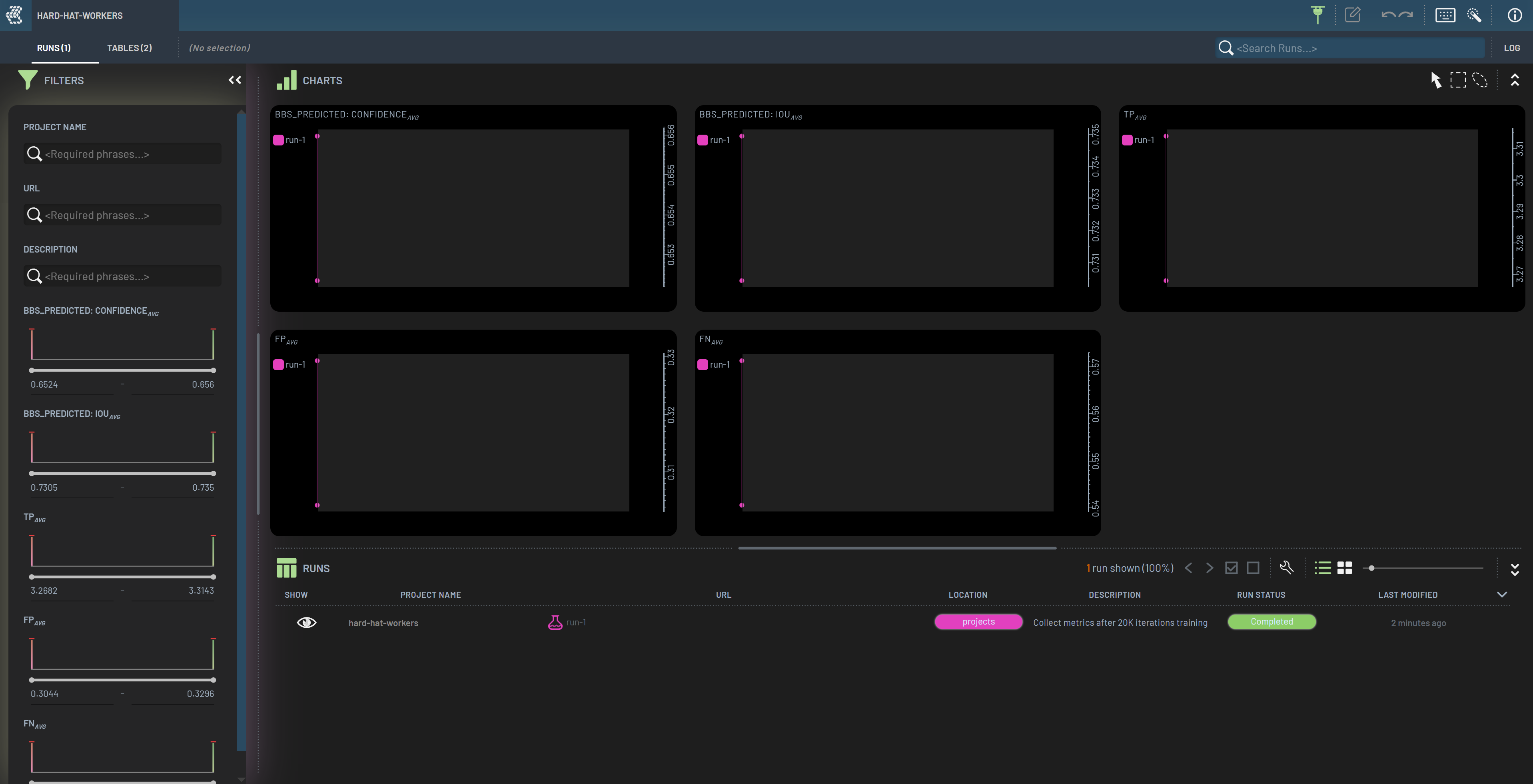
After DoubleClick’ing the “hard-hat-worker” Project on the front page, the Runs page will be displayed. Some aggregated metrics are plotted in the Charts panel, while all Runs are listed in the in the Rows panel. DoubleClick on the row labelled “run-1” to open this Run in the Dashboard.
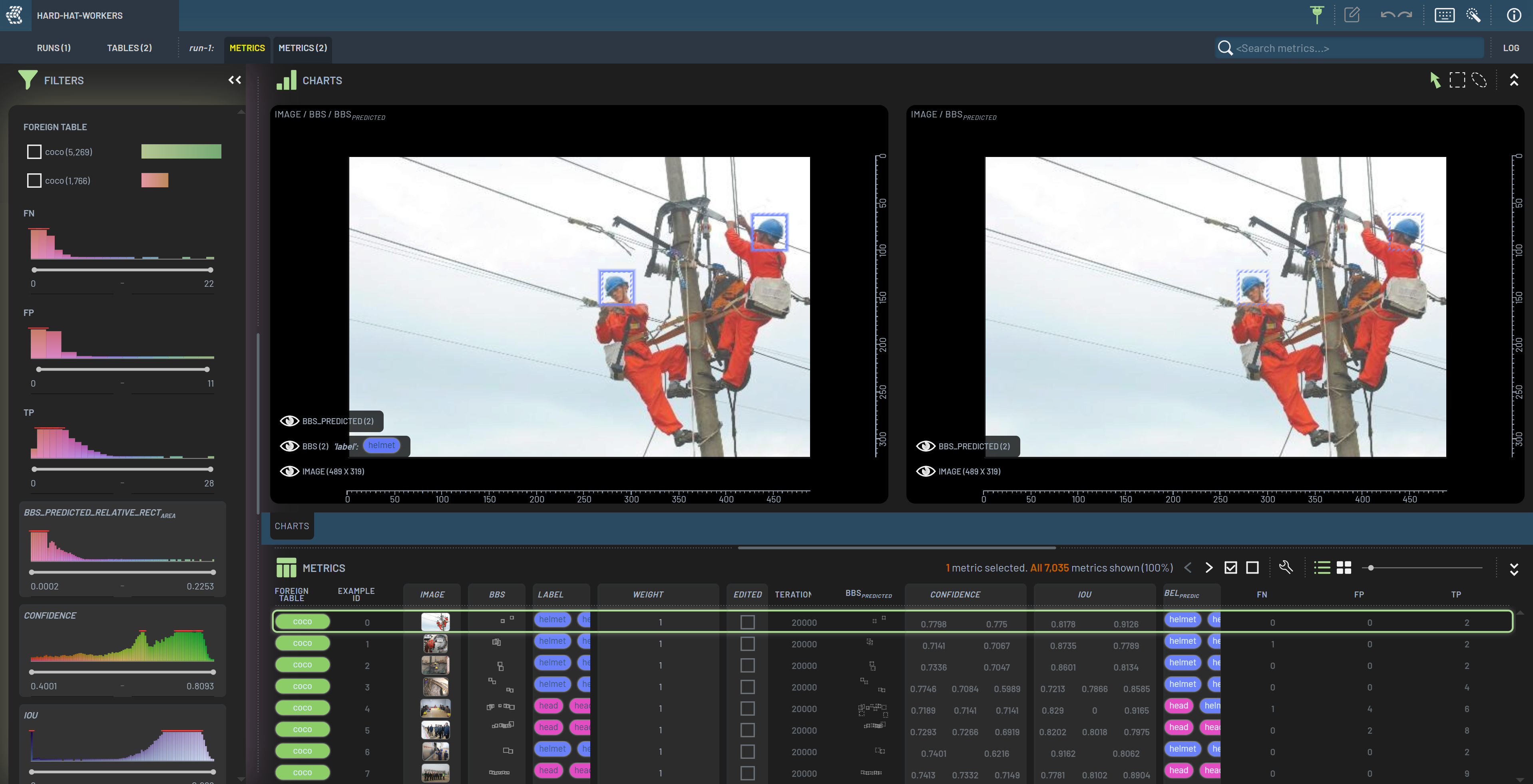
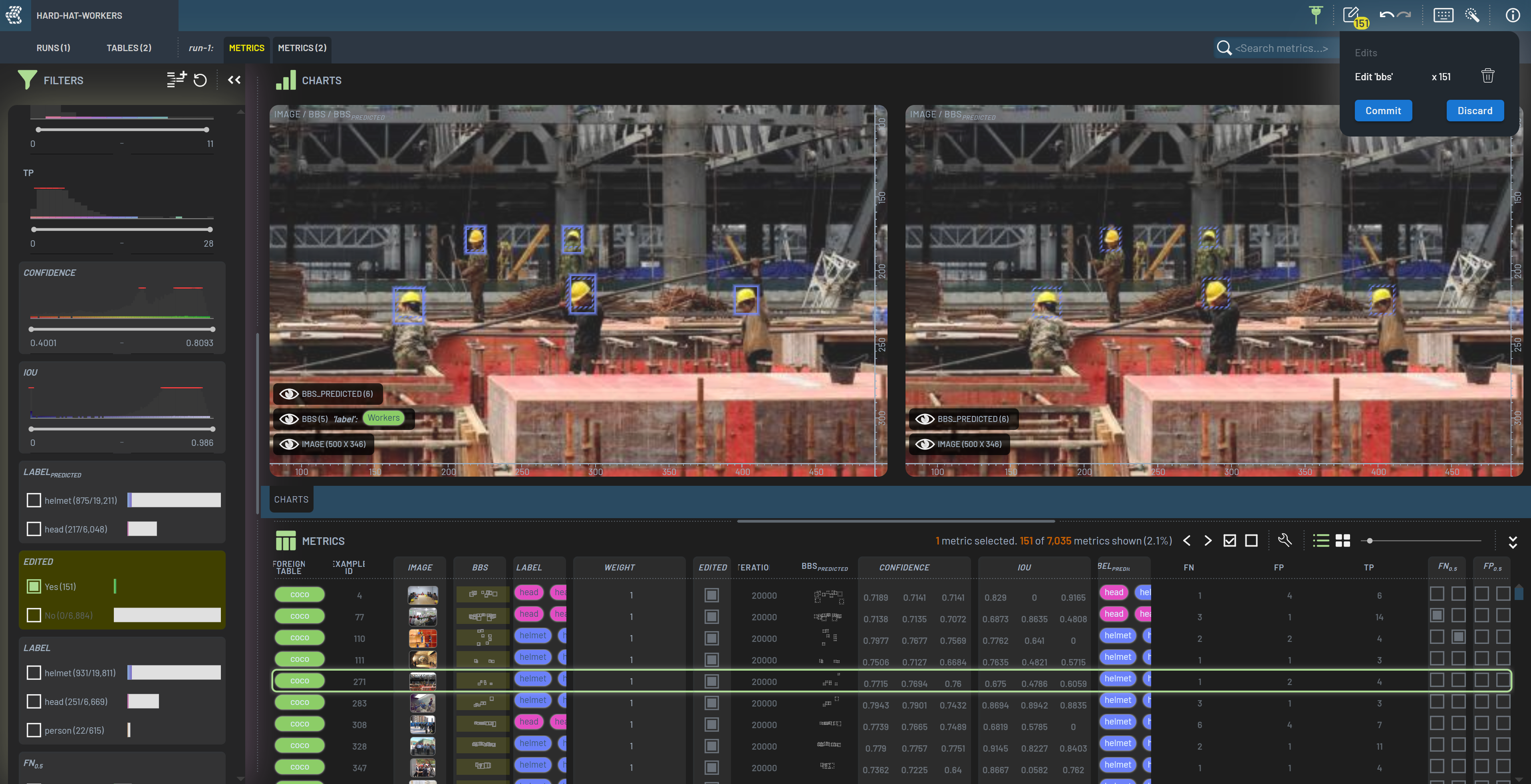
Each row of the now opened Run represents one inference pass over one sample of the hard hat dataset. Each row contains data about the sample itself, like image and bbs (ground truth bounding boxes), but also data collected using our model, like BBspredicted (predicted bounding boxes) and confidence.
In your code, you can specify exactly which metrics you want 3LC to collect. Let’s try to find some labeling issues in the hard hat dataset.
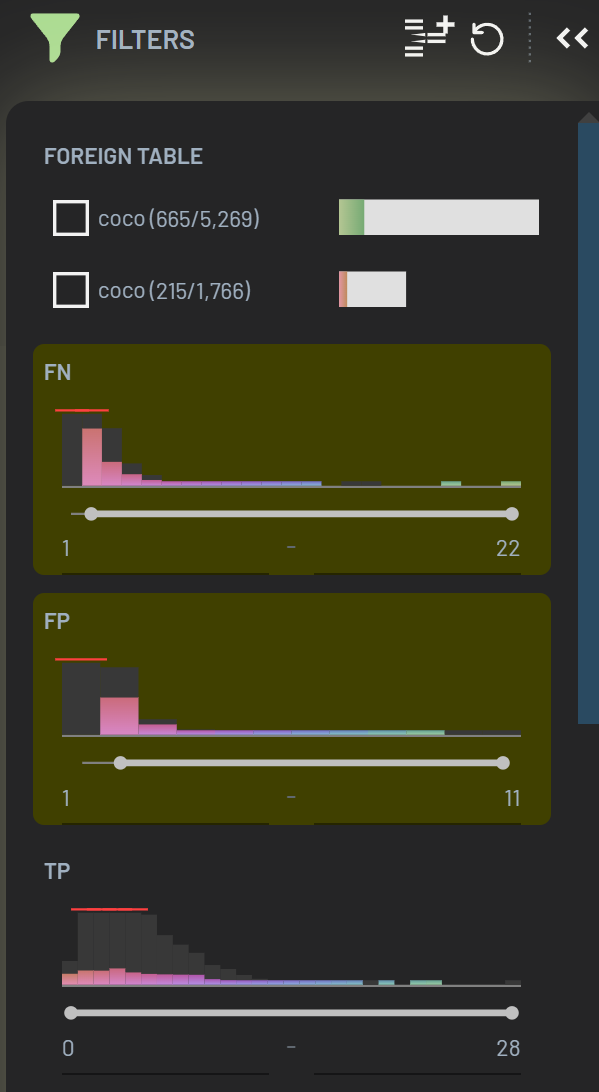
Most columns can be filtered on using the Filters panel. For numeric values, you can specify a value range to only show rows where the value falls within this range. Filtering on multiple columns at once narrows the search further. Let’s filter on rows which contain at least one false positive and at least one false negative.
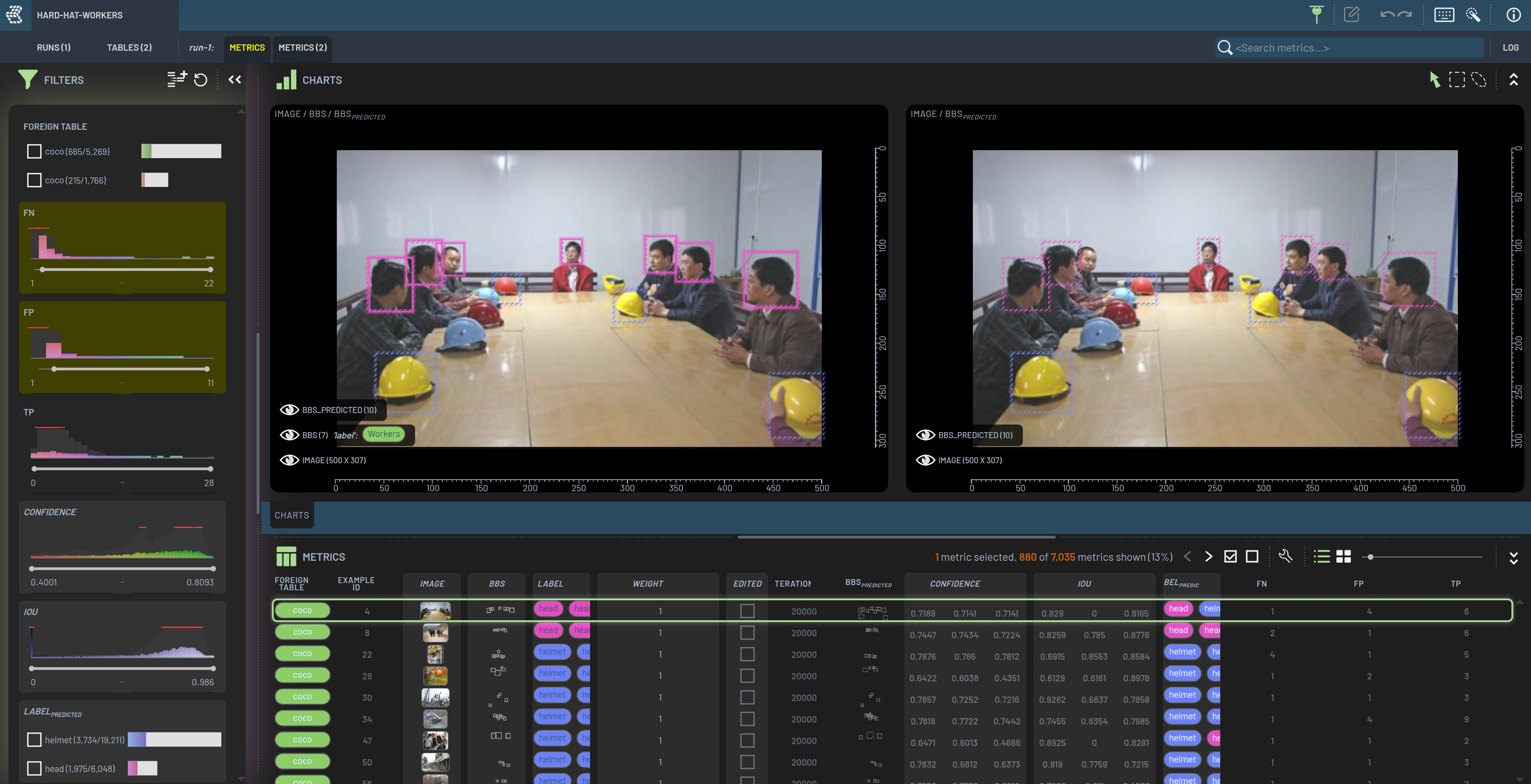
We can now see that the 7,035 rows of the dataset have been reduced to 880 rows which contain both false positives (FP) and false negatives (FN). These rows either represent challenging samples for the model or indicate issues with labeling.
When using these statically computed FP and FN metrics columns, we can only view the samples which contain them, requiring us to manually inspect each sample to find the labeling issues. Instead, we can use Virtual columns to dynamically compute and selectively filter on the specific bounding boxes which constitute FP and FN.
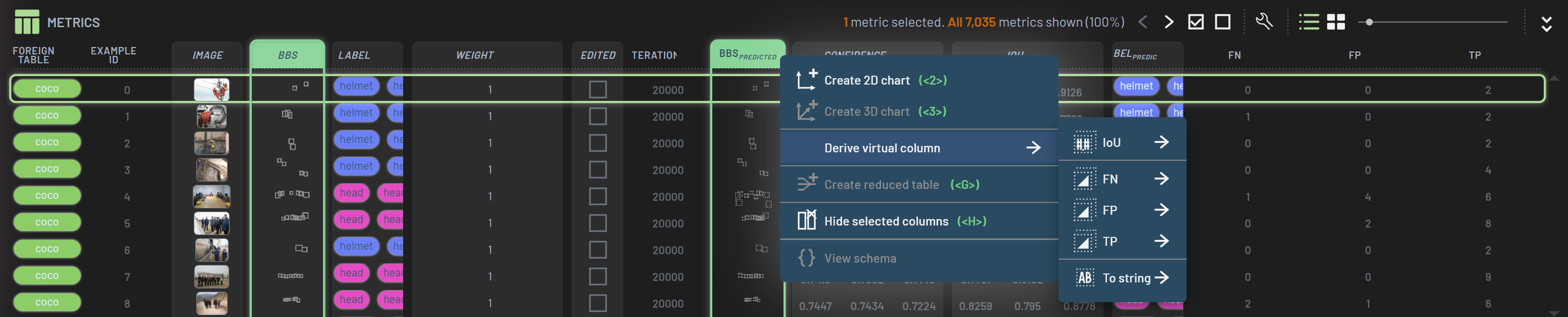
To compute these Virtual columns, select the BBs column and the BBspredicted column while holding Ctrl. Then, RightClick on one of the selected columns and hover over Derive virtual column. Here, LeftClick FN and FP to create two new columns.
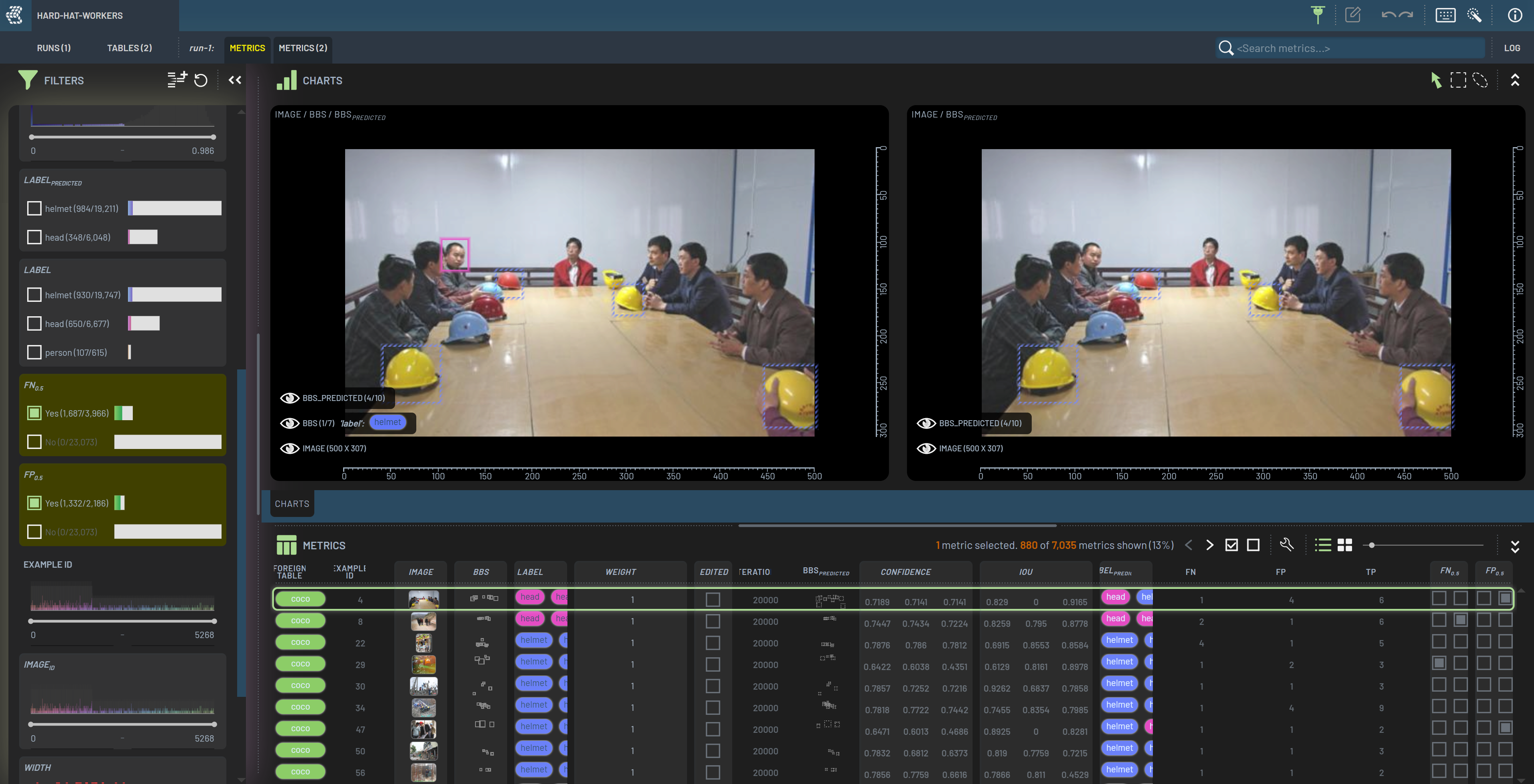
The FN and FP columns are added at the right end of the Rows panel. Their corresponding filter widgets are also added to the Filters panel. By selecting “Yes” for both of these filters, the exact same 880 rows will be displayed as before. However, now the images will only show the bounding boxes which constitute the false positives and false negatives. In addition to making it much easier to spot labeling issues, this per-bounding-box granularity allows us to further narrow down our search to bounding boxes with specific characteristics.
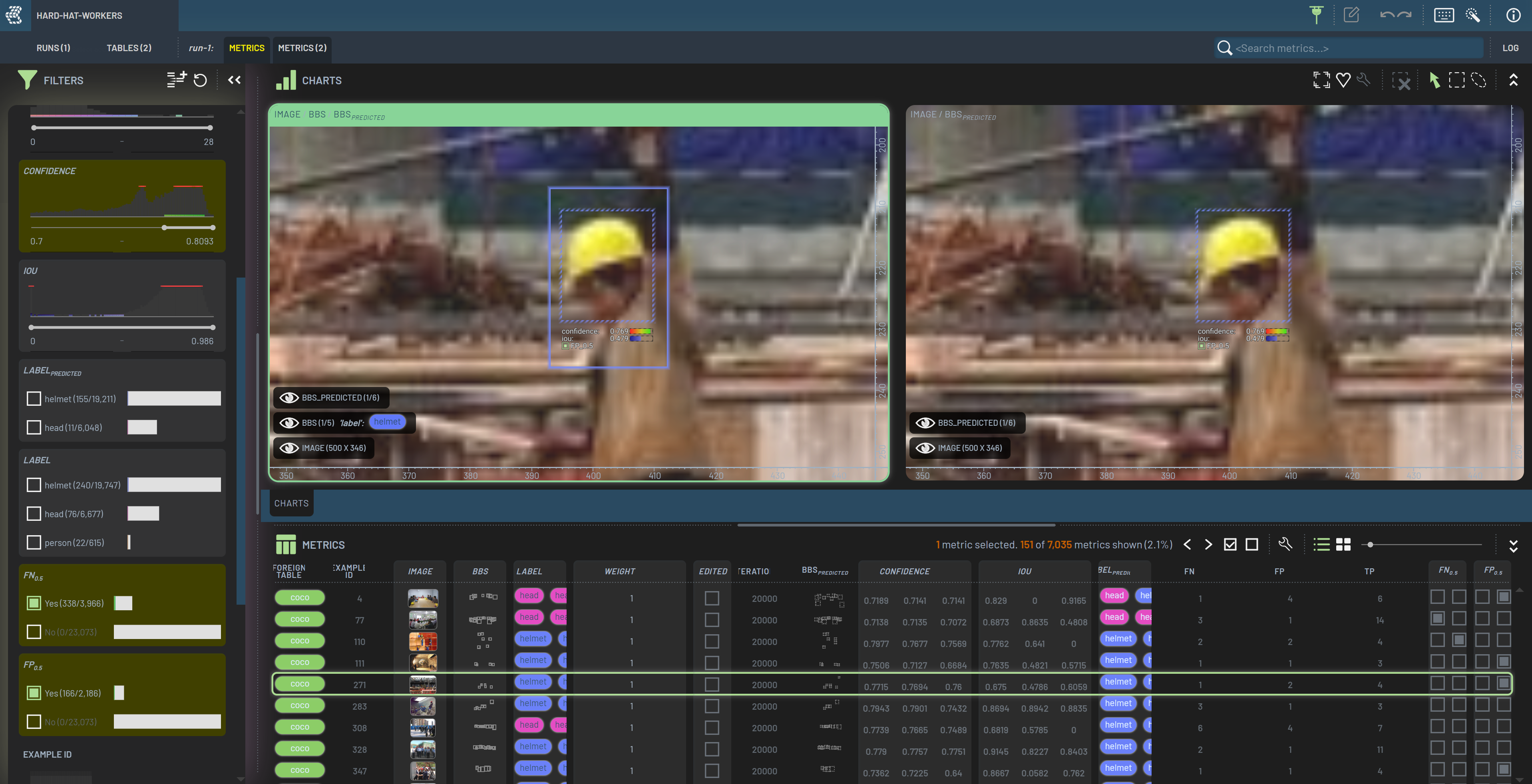
Let’s tweak the Confidence filter to only show predicted bounding boxes with a confidence of at least 0.7. This reduces the number of filtered-in rows to 151. The bounding boxes currently filtered in are ones which do not match the ground truth labels (as we are looking at FP), but which the model is nonetheless very confident in. This indicates that there are likely labeling issues in these samples. These issues could include bounding boxes having the wrong class, being the wrong size, or even outright missing.
When looking at an image with overlayed bounding boxes, we can select bad boxes by LeftClick’ing them. From here, we can either select a new class for the box, or delete it entirely by pressing the Delete key. If we want to replace the deleted bounding box with a prediction from the model, we can select the predicted bounding box we want to insert, RightClick, and then select Add prediction.
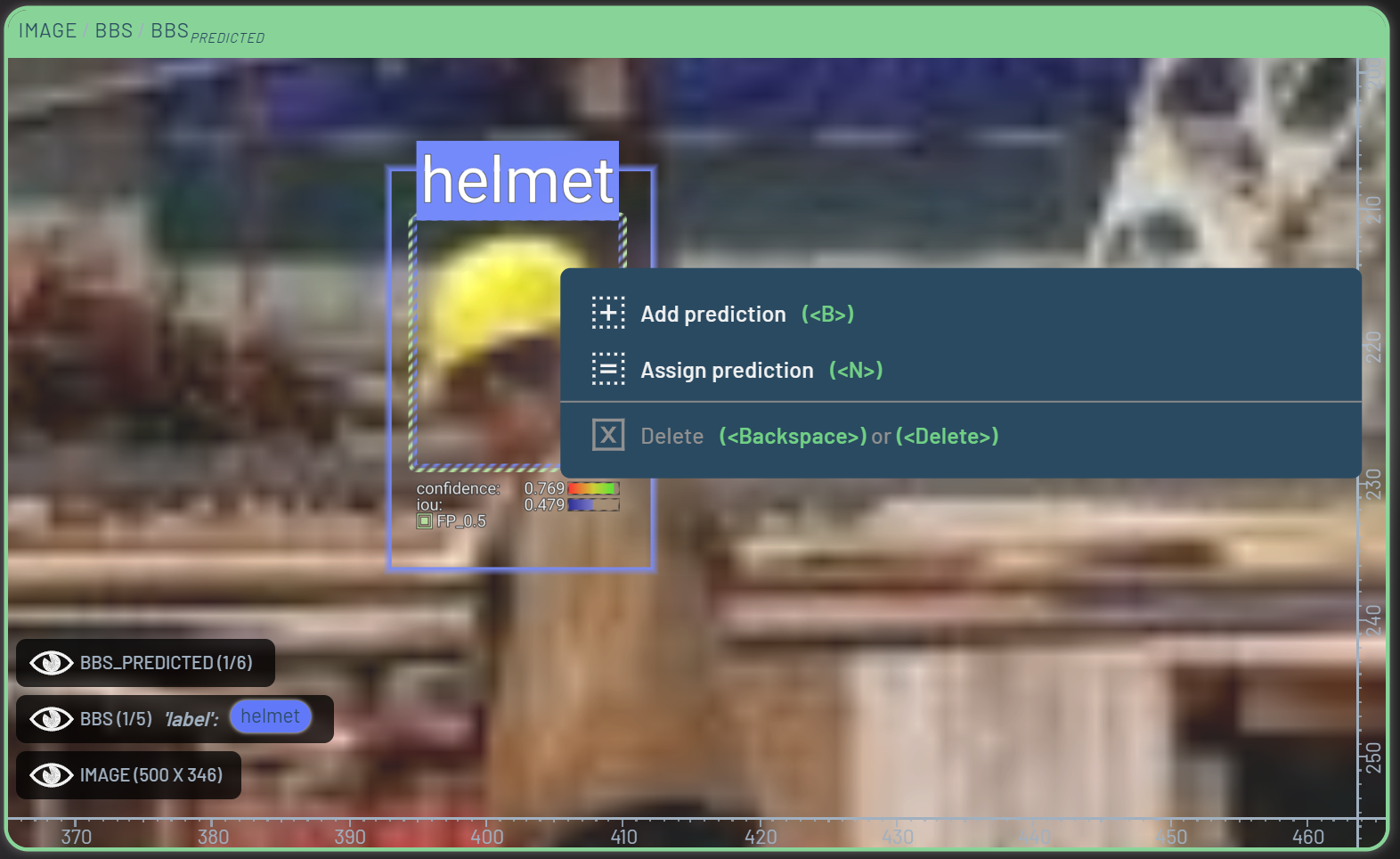
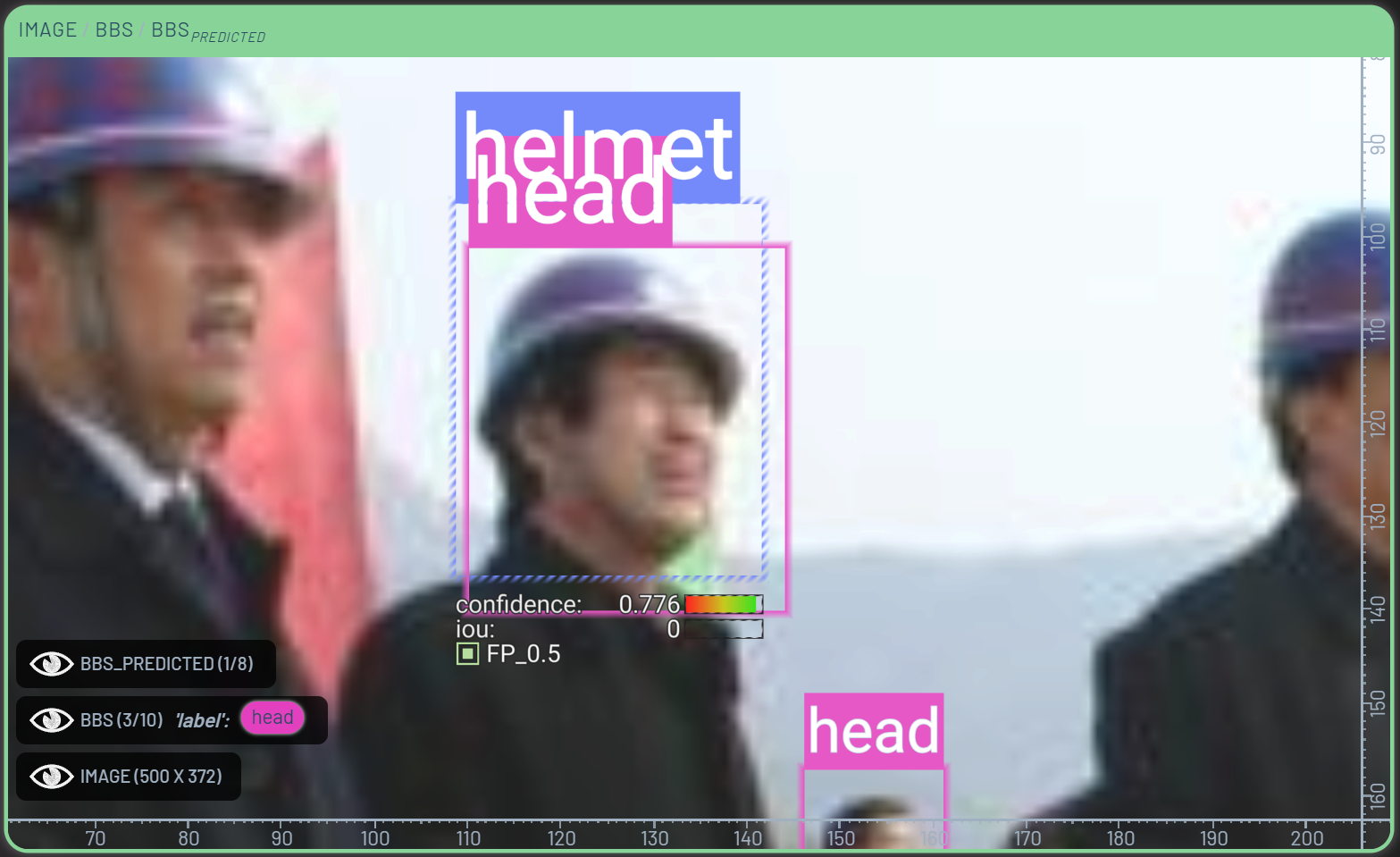
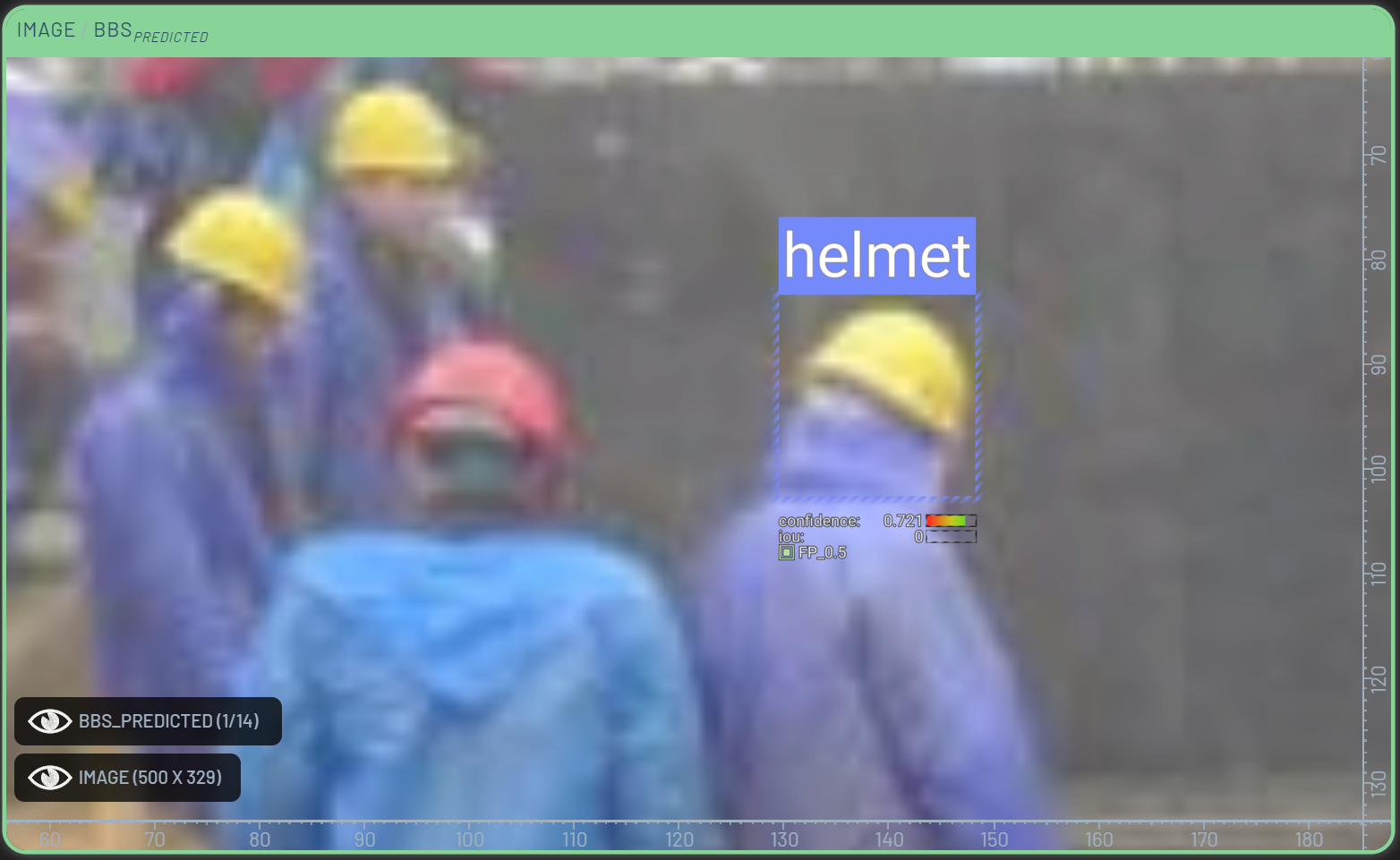
To expedite the common task of replacing ground truth labels with model predictions, we can configure the Dashboard to automatically delete ground truth labels when adding predictions if the two bounding boxes have a high enough intersection over union (IoU). This is done by RightClick’ing the BBs context menu in the bottom left corner of the Chart panel, and setting the Max IoU to a value between 0 and 1. For this example, we have set it to 0.3. When adding a prediction, the model will only replace the ground truth label if the IoU between the prediction and the ground truth label is higher than 0.3.
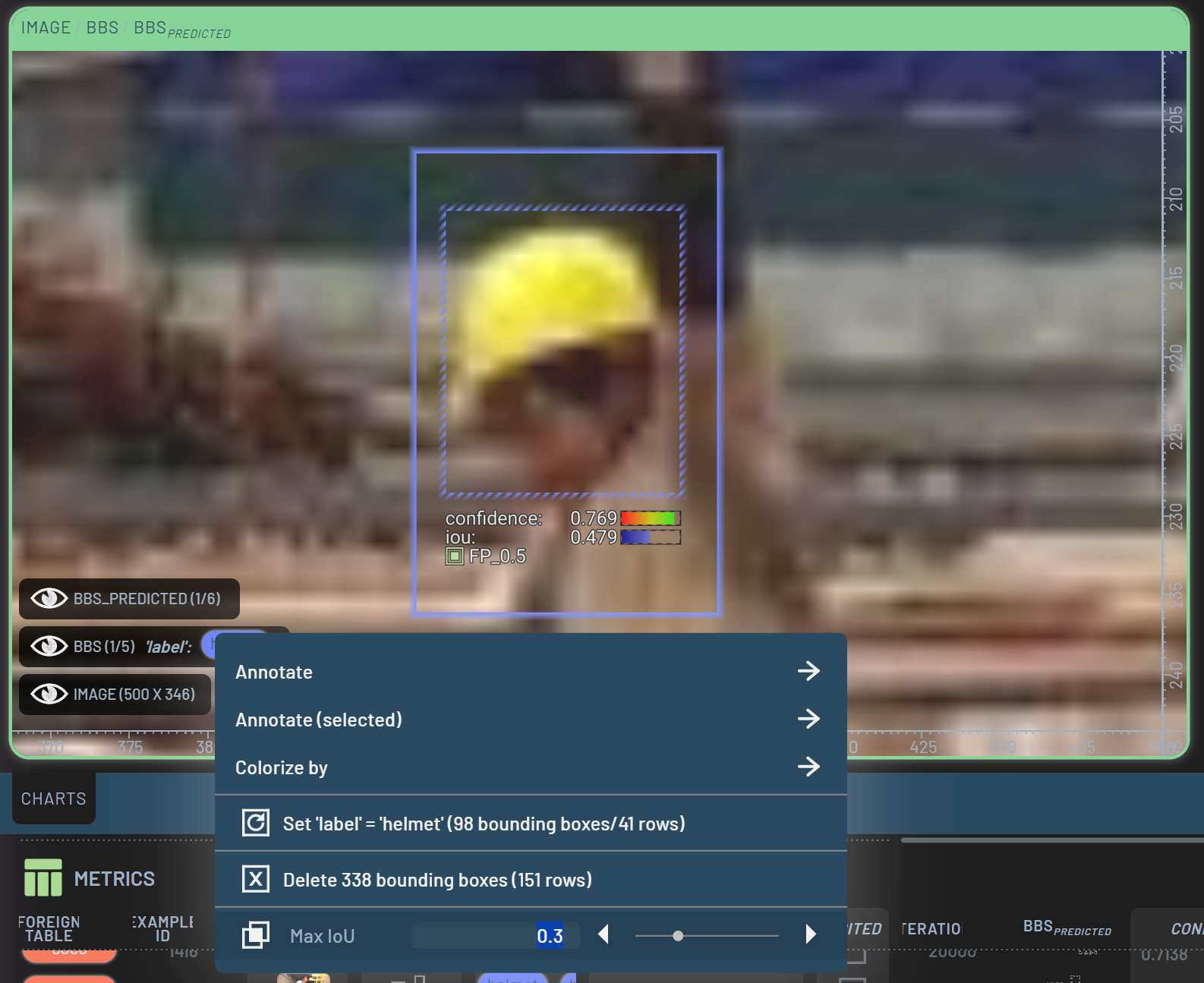
After reviewing a few images and feeling confident that the confidently predicted bounding boxes are indeed better than the ground truth labels, we can RightClick the BBspredicted context menu in the bottom left corner of the Chart panel, and select “Add 166 predictions (151 rows)”. This will add all of the predicted bounding boxes currently filtered in to the ground truth labels. If these predictions have an IoU higher than 0.3 with the ground truth labels, the ground truth labels will be replaced.
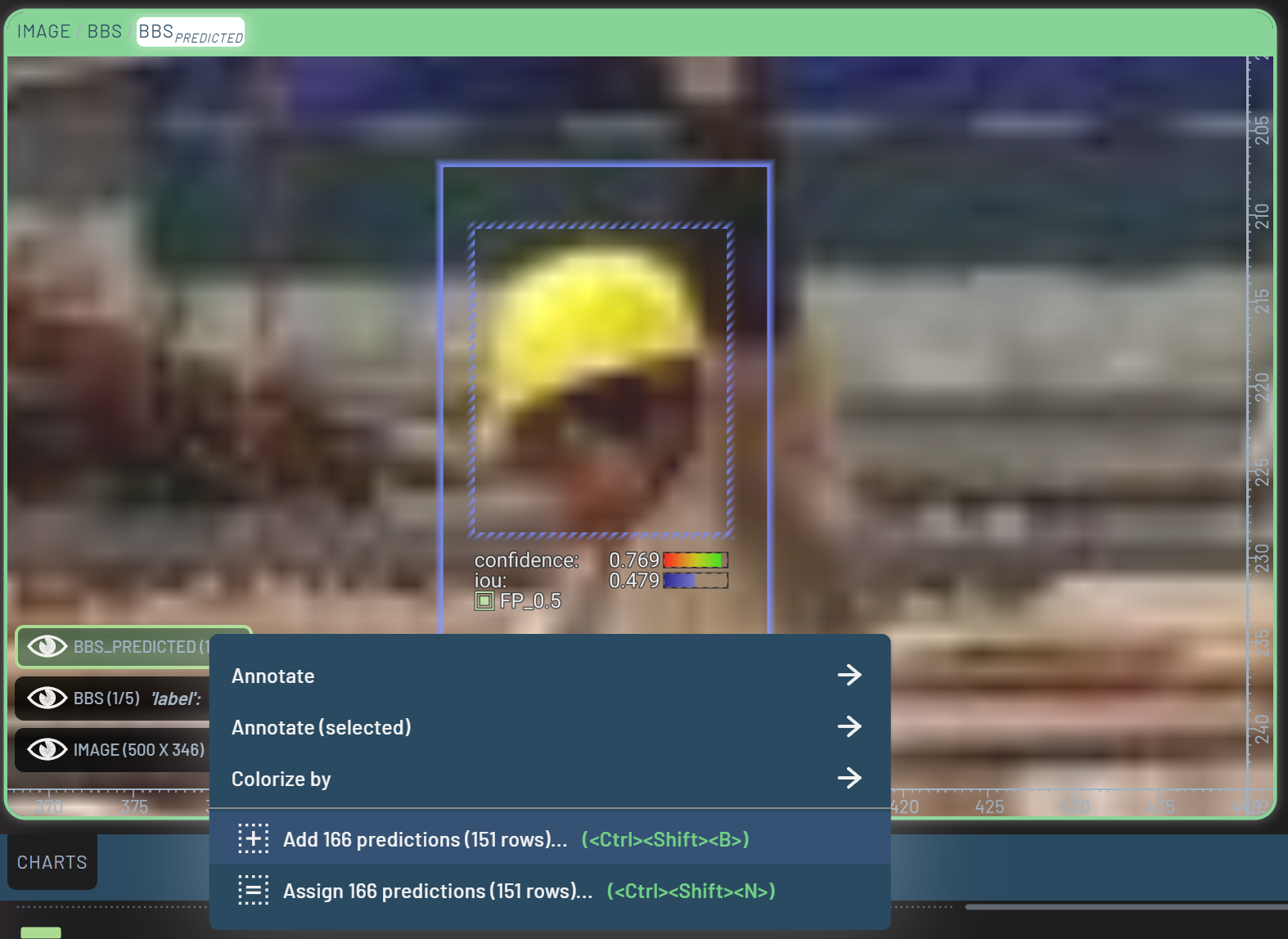
Note that once these edits are made, the edited rows will disappear from the Rows panel. This is because the filters are still active, and the edited rows no longer contain any false positives or false negatives. To see all rows again, simply clear the filters by pressing the reset icon at the top of the Filters panel. To review only the rows which you have edited, you can filter on the Edited property in the Filters panel.
Once we have cleaned up our dataset and are ready to run training again with our changes, we press the Commit button under the pen icon in the top right corner to commit our changes and create a new dataset revision. The next time we run our training, the changes we made in the Dashboard will automatically be reflected in the data passed to the model. With improved labels, retraining will likely result in a better model, which can again be used for further dataset improvements.