3LC Customer Managed Architecture¶
3LC (3 Lines of Code) is a tool for understanding and improving machine learning (ML) models and datasets. Powerful visualization tools, collection and analysis of custom metrics, and seamless editing of your dataset can all be unlocked with just 3 Lines of Code.
This document describes the software architecture of the 3LC system using the customer managed enterprise deployment, whether hosted in a private cloud or on-prem. The intended audience of this document is IT administrators tasked with deploying 3LC in such a customer managed environment. It is not intended as an end-user guide for using the system. For that, see the 3LC Documentation.
There is also a public version of 3LC where components are loaded over the public internet, which is beyond the scope of this document.
Introduction¶
3LC is designed to integrate into an existing machine learning workflow, where data-collection, data labelling, model training and deployment are already in place.
3LC hooks into an already existing Python script or notebook for machine learning, and turns model training into an iterative and interactive process where a data scientist can analyze and modify the training data. The end result is an improved model and dataset that will later be deployed to production, with increased performance and/or accuracy.

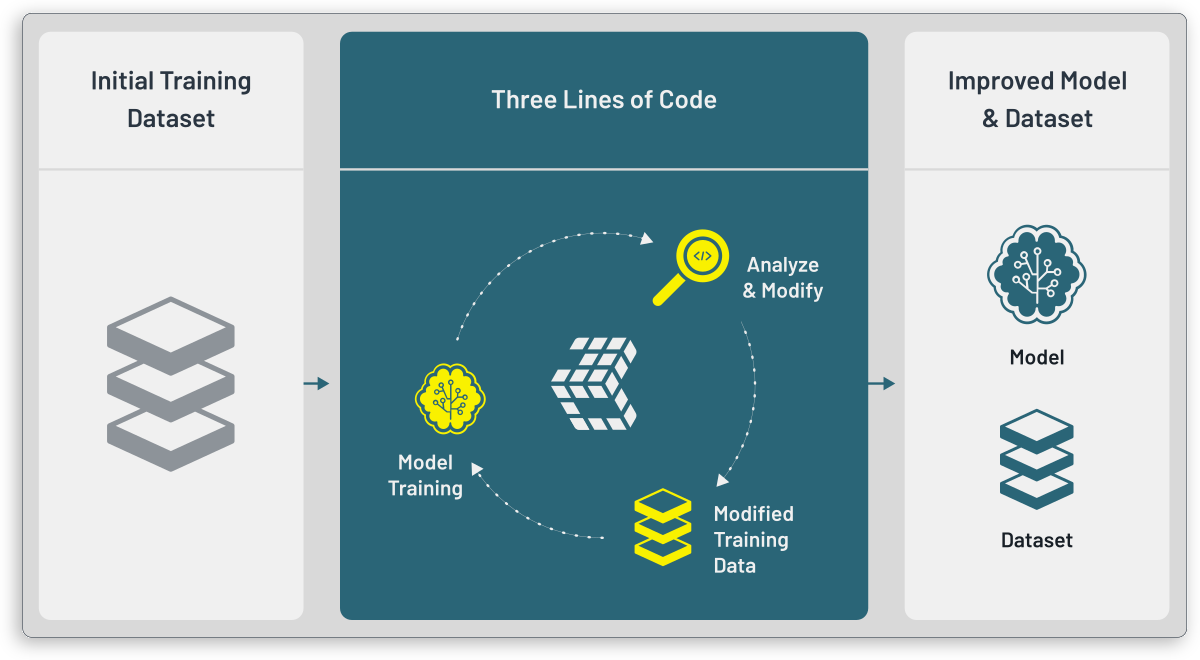
Context¶
Technically, a data scientist will access the 3LC system, while also having access to a ML training script. The training and 3LC both need to have access to the same storage backend, which stores the initial training data, metrics collected during training, and potentially revisions of the training data created by 3LC.
3LC provides a thin and sparse system to create revisions to training data. The source data remains unchanged, and 3LC provides sparse revisions on top of the source data, similar to source control systems such as Git.
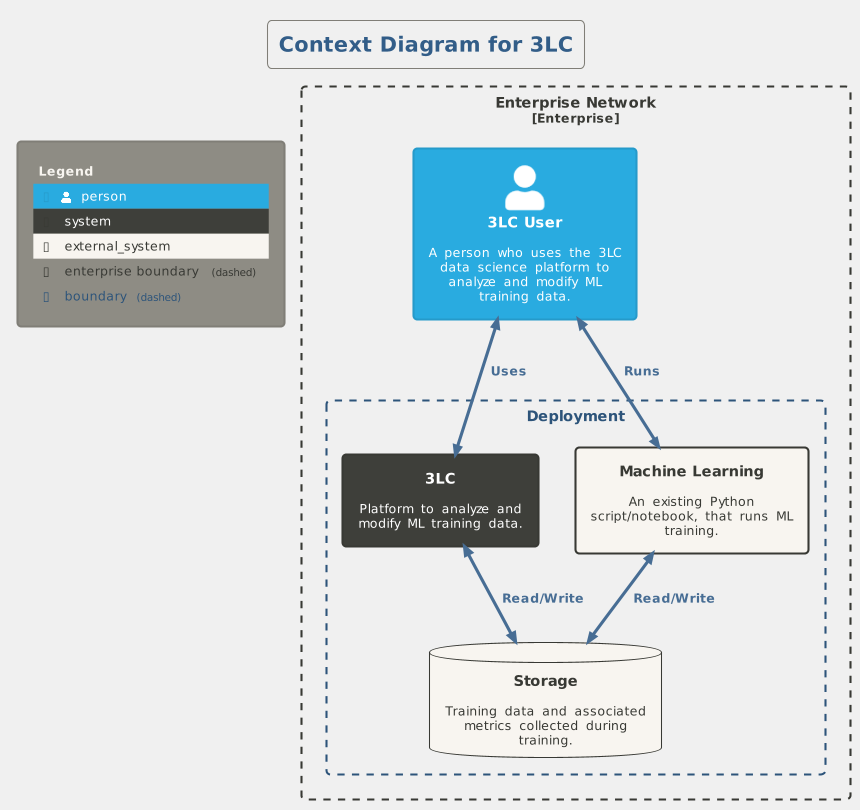
Context Diagram for 3LC¶
Since 3LC is designed to be deployed into existing ML workflows, it is quite flexible in how it is deployed. It is possible to deploy the system both on end-user workstations, on-prem (GPU) nodes, as well as on cloud infrastructure.
With the customer managed deployment, no communication occurs outside the enterprise network, other than a license check at startup of the 3LC Object Service.
3LC Components¶
3LC is composed of four main components:
The
tlcPython Package used to integrate with your existing ML code to capture metrics during trainingThe 3LC Object Service used to provide the 3LC Dashboard access to ML training data and metrics captured during training, requires access to the same storage backend as the training
The 3LC Dashboard web application used to analyze and make revisions to ML training data and metrics in the browser, combining static UI resources from the 3LC Dashboard Service with ML data accessed through the 3LC Object Service
The 3LC Dashboard Service used to serve static UI web resources (HTML, JavaScript) to the 3LC Dashboard
All of these components are made available by installing the 3lc-enterprise Python package, as described in the
Quickstart guide.
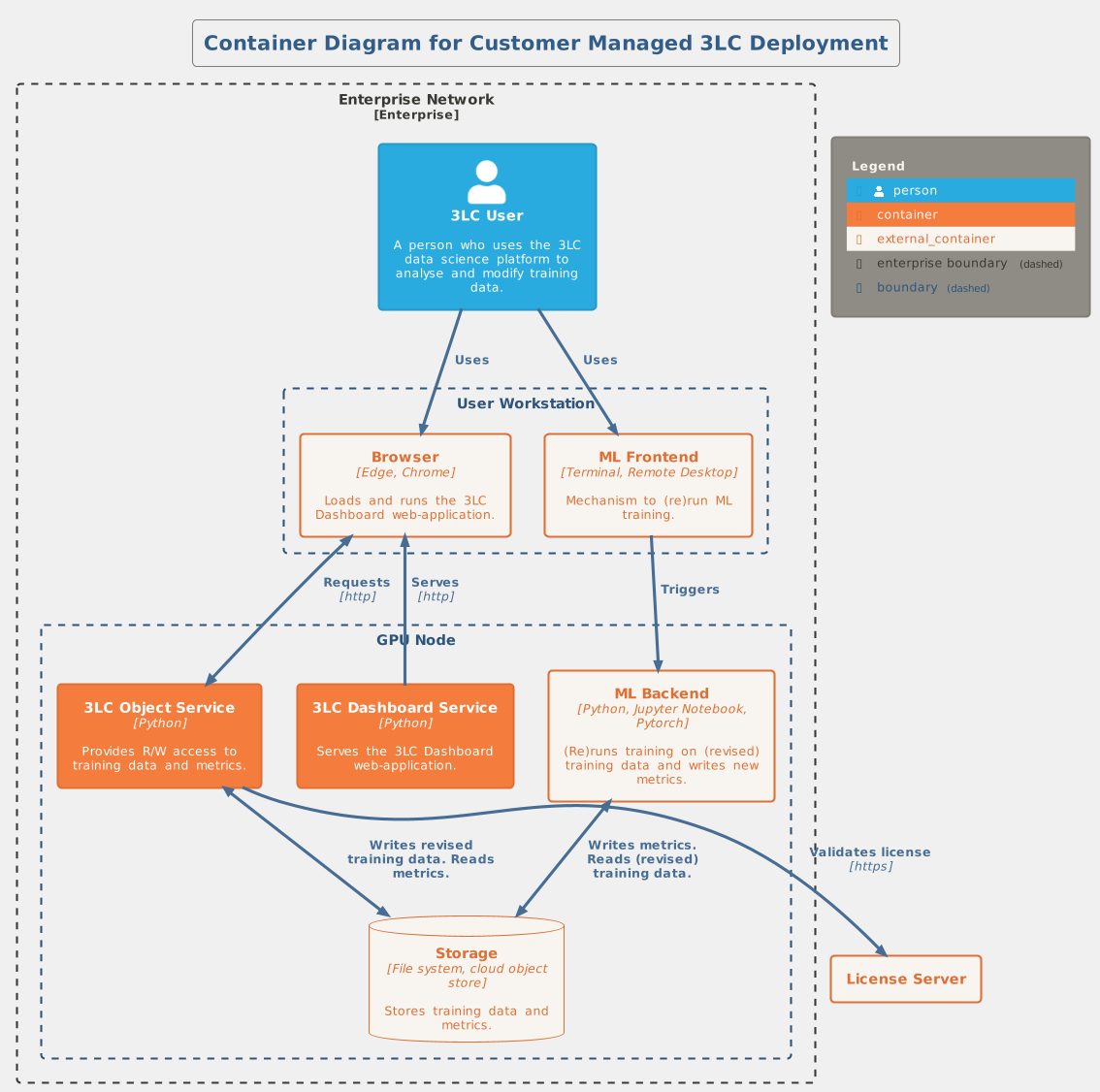
The figure below illustrates a possible deployment scenario when deploying on a GPU node. Here, the 3LC Object Service and 3LC Dashboard Service both run on the GPU node and the user loads the 3LC Dashboard in a local browser. This requires that the relevant ports (by default 5015 and 8000) be open for access from the user’s workstation.
Since the 3LC Dashboard provides interactive 2D- and 3D-plots, it is recommended that users access the 3LC Dashboard through a local web browser to get the highest performance, instead of using remote desktop technologies to run a browser on the GPU node.
Secure Communication¶
The 3LC Object Service indexes the sample and metric data that should be made available for browsing and potentially editing in the 3LC Dashboard. The Dashboard communicates with the Object Service via HTTP requests. The Object Service and the Dashboard may run on the same machine but often they run on different machines. Please see the Object Service Deployment Guide for details and options.
The primary source of security for communication between the Dashboard and the Object Service in the 3LC Enterprise Customer Managed deployment comes from the Object Service running on a machine that is part of the enterprise network without general internet access, which means that it is not exposed to threats from the open internet.
3LC provides a further mechanism to ensure that the Object Service only handles requests from trusted Dashboard instances. This is done by providing an authentication secret to both the Object Service and the Dashboard Service when starting them.
Part of the authentication check done in the Object Service is a comparison of the timestamp for the request, set based on the time of the machine running the Dashboard, against the current time of the machine running the Object Service. The difference is allowed to be up to five minutes, allowing for some delay in the time it takes a request from the Dashboard to reach the Object Service, but with a limit to protect against potential replay attacks. There can be issues with this check if there is significant skew (i.e. approaching or exceeding five minutes) between the time on the machine running the Dashboard and the machine running the Object Service. We recommend both machines be set to control time based on NTP so they automatically stay compatible.
The shared authentication secret should be a strong, random string known only to the Dashboard and Object Service. It can be specified via environment variables or via command-line arguments as illustrated in the sections below.
Using Environment Variables¶
On the machine where the Object Service will run:
set TLC_OBJECT_SERVICE_AUTH_SECRET=<AUTH_SECRET> 3lc service
export TLC_OBJECT_SERVICE_AUTH_SECRET=<AUTH_SECRET> 3lc service
On the machine where the Dashboard Service will run:
set TLC_OBJECT_SERVICE_AUTH_SECRET=<AUTH_SECRET> 3lc-dashboard
export TLC_OBJECT_SERVICE_AUTH_SECRET=<AUTH_SECRET> 3lc-dashboard
Using Command-Line Arguments¶
On the machine where the Object Service will run:
3lc service --auth-secret <AUTH_SECRET>
On the machine where the Dashboard Service will run:
3lc-dashboard --object-service-auth-secret <AUTH_SECRET>