Ingest PandaSet autonomous driving dataset¶
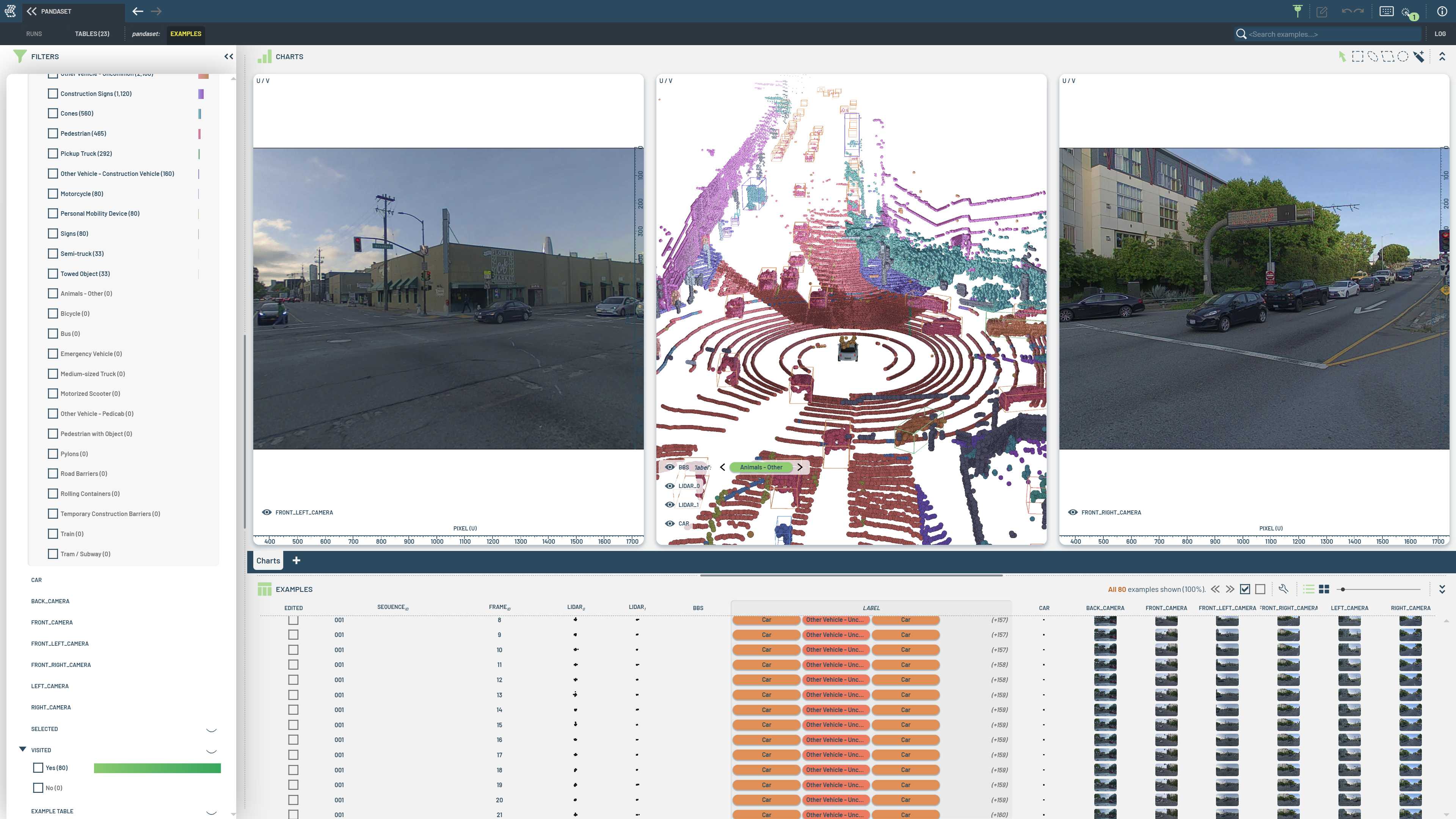
This notebook shows how to load 3D point clouds, 3D oriented bounding boxes and semantic segmentations from the PandaSet dataset into a 3LC Table.
Tables with large 3D geometries use the bulk data pattern for storing data. For details on the ingestion process, see the loading script
Running this notebook requires the PandaSet DevKit.
The dataset can be downloaded from HuggingFace. If you have already downloaded pandaset.zip, ensure the dataset root below points to the unzipped pandaset directory.
If not, the notebook will download pandaset.zip and unzip it into the dataset root directory. This requires authentication with HuggingFace, for example by setting the HF_TOKEN environment variable.
⚠️ Storage requirements
The unzipped dataset is ~42GB, and ingesting all sequences into 3LC will require another 50GB of disk space. Ensure you have enough free space before running the notebook.
Project Setup¶
[ ]:
PROJECT_NAME = "3LC Tutorials - Pandaset"
DATASET_NAME = "pandaset"
TABLE_NAME = "pandaset"
DATA_PATH = "../../../../data"
DOWNLOAD_PATH = "../../../../transient_data"
MAX_FRAMES = None
MAX_SEQUENCES = None
INSTALL_DEPENDENCIES = True
[ ]:
if INSTALL_DEPENDENCIES:
%pip install -q "pandaset @ git+https://github.com/scaleapi/pandaset-devkit.git@master#subdirectory=python"
%pip install -q 3lc
%pip install -q huggingface-hub
Imports¶
Prepare Dataset¶
[ ]:
DATASET_ROOT = Path(DOWNLOAD_PATH) / "pandaset"
if not DATASET_ROOT.exists():
import zipfile
from huggingface_hub import hf_hub_download
print("Downloading dataset from HuggingFace")
hf_hub_download(
repo_id="georghess/pandaset",
repo_type="dataset",
filename="pandaset.zip",
local_dir=DATASET_ROOT.parent.absolute().as_posix(),
)
with zipfile.ZipFile(f"{DATASET_ROOT.parent}/pandaset.zip", "r") as zip_ref:
zip_ref.extractall(DATASET_ROOT.parent)
# Remove the pandaset.zip file after extraction
(DATASET_ROOT.parent / "pandaset.zip").unlink(missing_ok=True)
else:
print(f"Dataset root {DATASET_ROOT} already exists")
Create Table¶
[ ]:
table = load_pandaset(
dataset_root=DATASET_ROOT,
table_name=TABLE_NAME,
dataset_name=DATASET_NAME,
project_name=PROJECT_NAME,
data_path=DATA_PATH,
max_frames=MAX_FRAMES,
max_sequences=MAX_SEQUENCES,
)