Fine-tuning a SegFormer model with Pytorch Lightning¶
This notebook fine-tunes a SegFormer model for semantic segmentation using PyTorch Lightning.
The original notebook can be found here.
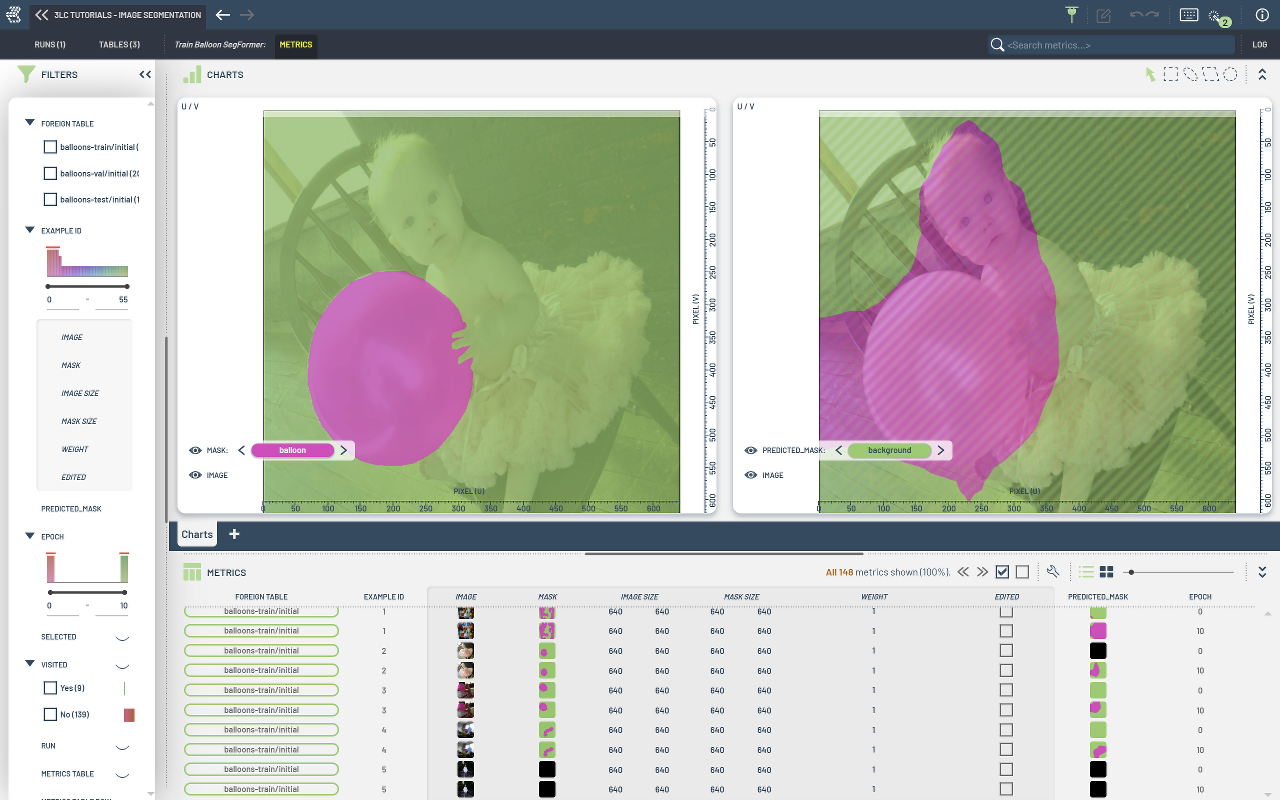
In this tutorial we fine-tune a pre-trained SegFormer model for semantic segmentation on a custom dataset. We integrate with 3LC by creating Tables up front, initializing a Run, and collecting per-sample predicted masks from raw Lightning hooks.
This notebook demonstrates:
Training a SegFormer model on a custom dataset with PyTorch Lightning.
Registering train/val/test sets into 3LC Tables.
Collecting per-sample semantic segmentation predicted masks via
tlc.collect_metricscalled fromon_train_epoch_end/on_train_end.
Project Setup¶
[ ]:
PROJECT_NAME = "3LC Tutorials - Image Segmentation"
RUN_NAME = "Train Balloon SegFormer"
DESCRIPTION = "Train a SegFormer model using PyTorch Lightning"
TRAIN_DATASET_NAME = "balloons-train"
VAL_DATASET_NAME = "balloons-val"
TEST_DATASET_NAME = "balloons-test"
SEGFORMER_MODEL_ID = "nvidia/mit-b0"
DATA_PATH = "../../data"
EPOCHS = 10
BATCH_SIZE = 8
NUM_WORKERS = 0
DEVICE = None
LEARNING_RATE = 2e-05
INSTALL_DEPENDENCIES = True
Install dependencies¶
[ ]:
if INSTALL_DEPENDENCIES:
%pip install -q 3lc[huggingface]
%pip install -q pytorch-lightning
%pip install -q matplotlib
Imports¶
[ ]:
import os
import numpy as np
import pytorch_lightning as pl
import tlc
import torch
from evaluate import load
from matplotlib import pyplot as plt
from PIL import Image
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks.model_checkpoint import ModelCheckpoint
from tlc.integration.torch.samplers import create_sampler
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import VisionDataset
from transformers import SegformerForSemanticSegmentation, SegformerImageProcessor
[ ]:
if DEVICE is None:
if torch.cuda.is_available():
device = "cuda:0"
elif torch.backends.mps.is_available():
# Disable MPS due to tensor view issues with SegFormer
device = "cpu"
else:
device = "cpu"
else:
device = DEVICE
device = torch.device(device)
print(f"Using device: {device}")
Setup Datasets and Training helpers¶
We will create a Table with the images and their associated masks.
Moreover, we will also define helpers to pre-process this dataset into a suitable form for training and collecting metrics.
To finish, we define a Pytorch LightningModule to define the steps for training, validation and test.
[ ]:
class TLCSemanticSegmentationDataset(VisionDataset):
"""Image (semantic) segmentation dataset."""
def __init__(self, root_dir):
super().__init__(root_dir)
self.root_dir = root_dir
image_file_names = [f for f in os.listdir(self.root_dir) if ".jpg" in f]
mask_file_names = [f for f in os.listdir(self.root_dir) if ".png" in f]
self.images = sorted(image_file_names)
self.masks = sorted(mask_file_names)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = Image.open(os.path.join(self.root_dir, self.images[idx]))
segmentation_map = Image.open(os.path.join(self.root_dir, self.masks[idx]))
return image, segmentation_map, segmentation_map.width, segmentation_map.height
[ ]:
def get_id2label(root_dir):
classes_csv_file = os.path.join(root_dir, "_classes.csv")
with open(classes_csv_file) as fid:
data = [line.split(",") for idx, line in enumerate(fid) if idx != 0]
# transformers >=5 requires int keys for `id2label`.
return {int(float(x[0])): x[1].strip() for x in data}
image_processor = SegformerImageProcessor.from_pretrained(SEGFORMER_MODEL_ID)
image_processor.do_reduce_labels = False
image_processor.size = 128
dataset_location = tlc.Url(DATA_PATH + "/balloons-mask-segmentation").to_absolute()
id2label = get_id2label(f"{dataset_location}/train/") # Assuming the same classes for train, val, and test
model = SegformerForSemanticSegmentation.from_pretrained(
SEGFORMER_MODEL_ID,
num_labels=len(id2label.keys()),
id2label=id2label,
label2id={v: k for k, v in id2label.items()},
ignore_mismatched_sizes=True,
)
[ ]:
schema = {
"image": tlc.schemas.ImageSchema(),
"segmentation_map": tlc.schemas.SemanticSegmentationSchema(classes=id2label),
"mask_width": tlc.schemas.Int32Schema(),
"mask_height": tlc.schemas.Int32Schema(),
# `TableWriter` doesn't add a weight column by default; we add one explicitly
# so the 3LC sampler has weights to draw from.
"weight": tlc.schemas.SampleWeightSchema(),
}
def mc_preprocess_fn(batch, predictor_output):
"""Transform a batch of inputs and model outputs to a format expected by the metrics collector."""
original_mask_size = batch["mask_size"].tolist()
outputs = predictor_output.forward
predicted_masks = image_processor.post_process_semantic_segmentation(
outputs=outputs,
target_sizes=original_mask_size,
)
return batch, predicted_masks
segmentation_metrics_collector = tlc.metrics.SegmentationMetricsCollector(
label_map=id2label,
preprocess_fn=mc_preprocess_fn,
)
[ ]:
################## 3LC ##################
# Create the 3LC Tables up front, OUTSIDE the LightningModule. This sidesteps DDP
# coordination inside `train_dataloader()`: each rank simply opens the same Table from disk.
def transforms(sample):
encoded_inputs = image_processor(sample["image"], sample["segmentation_map"], return_tensors="pt")
for k in encoded_inputs:
encoded_inputs[k] = encoded_inputs[k].squeeze() # remove batch dimension
# Add the original mask size so we can resize the predicted mask back later.
encoded_inputs["mask_size"] = torch.tensor([sample["mask_width"], sample["mask_height"]])
return dict(encoded_inputs)
def write_balloons_table(root_dir, dataset_name):
"""Stream a balloons split into a 3LC Table via TableWriter."""
dataset = TLCSemanticSegmentationDataset(root_dir)
writer = tlc.TableWriter(
project_name=PROJECT_NAME,
dataset_name=dataset_name,
schema=schema,
if_exists="overwrite",
)
images, masks, widths, heights = [], [], [], []
for image, segmentation_map, mask_width, mask_height in dataset:
images.append(image)
masks.append(segmentation_map)
widths.append(mask_width)
heights.append(mask_height)
writer.add_batch(
{
"image": images,
"segmentation_map": masks,
"mask_width": widths,
"mask_height": heights,
"weight": [1.0] * len(images),
}
)
return writer.finalize()
train_table = write_balloons_table(f"{dataset_location}/train/", TRAIN_DATASET_NAME)
val_table = write_balloons_table(f"{dataset_location}/valid/", VAL_DATASET_NAME)
test_table = write_balloons_table(f"{dataset_location}/test/", TEST_DATASET_NAME)
#########################################
[ ]:
class SegformerFinetuner(pl.LightningModule):
def __init__(
self,
model,
id2label,
train_table,
val_table,
test_table,
metrics_interval=100,
learning_rate=2e-05,
):
super().__init__()
self.save_hyperparameters(ignore=["model", "id2label", "train_table", "val_table", "test_table"])
self.train_table = train_table
self.val_table = val_table
self.test_table = test_table
self.metrics_interval = metrics_interval
self.learning_rate = learning_rate
self.id2label = id2label
self.num_classes = len(id2label.keys())
self.model = model
self.train_mean_iou = load("mean_iou")
self.val_mean_iou = load("mean_iou")
self.test_mean_iou = load("mean_iou")
self.training_step_outputs = []
self.validation_step_outputs = []
self.test_step_outputs = []
self.tlc_run: tlc.Run | None = None
def forward(self, images, masks=None):
outputs = self.model(images, masks)
return outputs
def training_step(self, batch, batch_idx):
images, masks = batch["pixel_values"], batch["labels"]
outputs = self(images, masks)
loss, logits = outputs[0], outputs[1]
upsampled_logits = nn.functional.interpolate(
logits, size=masks.shape[-2:], mode="bilinear", align_corners=False
)
predicted = upsampled_logits.argmax(dim=1)
self.train_mean_iou.add_batch(
predictions=predicted.detach().cpu().numpy(),
references=masks.detach().cpu().numpy(),
)
if batch_idx % self.metrics_interval == 0:
metrics = self.train_mean_iou.compute(
num_labels=self.num_classes,
ignore_index=255,
reduce_labels=False,
)
metrics = {
"loss": loss,
"mean_iou": metrics["mean_iou"],
"mean_accuracy": metrics["mean_accuracy"],
}
for k, v in metrics.items():
self.log(k, v, prog_bar=True)
tlc.log(
{
**{k: v.item() for k, v in metrics.items()},
"step": self.global_step,
}
)
else:
metrics = {"loss": loss}
self.training_step_outputs.append(metrics)
return metrics
def validation_step(self, batch):
images, masks = batch["pixel_values"], batch["labels"]
outputs = self(images, masks)
loss, logits = outputs[0], outputs[1]
upsampled_logits = nn.functional.interpolate(
logits, size=masks.shape[-2:], mode="bilinear", align_corners=False
)
predicted = upsampled_logits.argmax(dim=1)
self.val_mean_iou.add_batch(
predictions=predicted.detach().cpu().numpy(),
references=masks.detach().cpu().numpy(),
)
self.validation_step_outputs.append(loss)
return {"val_loss": loss}
def on_validation_epoch_end(self):
metrics = self.val_mean_iou.compute(
num_labels=self.num_classes,
ignore_index=255,
reduce_labels=False,
)
avg_val_loss = torch.stack(self.validation_step_outputs).mean()
val_mean_iou = metrics["mean_iou"]
val_mean_accuracy = metrics["mean_accuracy"]
metrics = {
"val_loss": avg_val_loss,
"val_mean_iou": val_mean_iou,
"val_mean_accuracy": val_mean_accuracy,
}
for k, v in metrics.items():
self.log(k, v, prog_bar=True)
self.validation_step_outputs.clear()
if not self.trainer.sanity_checking:
tlc.log(
{
**{k: v.item() for k, v in metrics.items()},
"step": self.global_step,
}
)
return metrics
def test_step(self, batch):
images, masks = batch["pixel_values"], batch["labels"]
outputs = self(images, masks)
loss, logits = outputs[0], outputs[1]
upsampled_logits = nn.functional.interpolate(
logits, size=masks.shape[-2:], mode="bilinear", align_corners=False
)
predicted = upsampled_logits.argmax(dim=1)
self.test_mean_iou.add_batch(
predictions=predicted.detach().cpu().numpy(),
references=masks.detach().cpu().numpy(),
)
self.test_step_outputs.append(loss)
return {"test_loss": loss}
def on_test_epoch_end(self):
metrics = self.test_mean_iou.compute(
num_labels=self.num_classes,
ignore_index=255,
reduce_labels=False,
)
avg_test_loss = torch.stack(self.test_step_outputs).mean()
test_mean_iou = metrics["mean_iou"]
test_mean_accuracy = metrics["mean_accuracy"]
metrics = {
"test_loss": avg_test_loss,
"test_mean_iou": test_mean_iou,
"test_mean_accuracy": test_mean_accuracy,
}
for k, v in metrics.items():
self.log(k, v)
self.test_step_outputs.clear()
return metrics
def configure_optimizers(self):
return torch.optim.Adam(
[p for p in self.parameters() if p.requires_grad],
lr=self.learning_rate,
eps=1e-08,
)
def train_dataloader(self):
return DataLoader(
self.train_table.with_transform(transforms),
sampler=create_sampler(self.train_table, weighted=True, exclude_zero_weights=True),
batch_size=BATCH_SIZE,
num_workers=NUM_WORKERS,
)
def val_dataloader(self):
return DataLoader(
self.val_table.with_transform(transforms),
batch_size=BATCH_SIZE,
num_workers=NUM_WORKERS,
)
def test_dataloader(self):
return DataLoader(
self.test_table.with_transform(transforms),
batch_size=BATCH_SIZE,
num_workers=NUM_WORKERS,
)
################## 3LC ##################
def on_train_start(self):
super().on_train_start()
self.tlc_run = tlc.init(
project_name=PROJECT_NAME,
run_name=RUN_NAME,
description=DESCRIPTION,
parameters=dict(self.hparams_initial),
if_exists="overwrite",
)
self.tlc_run.set_status_running()
def on_train_end(self):
super().on_train_end()
self._collect_3lc_metrics()
if self.tlc_run is not None:
self.tlc_run.set_status_completed()
def _collect_3lc_metrics(self):
predictor = tlc.metrics.Predictor(self)
for split, table in [("train", self.train_table), ("val", self.val_table)]:
tlc.collect_metrics(
table=table.with_transform(transforms),
metrics_collectors=[segmentation_metrics_collector],
predictor=predictor,
split=split,
constants={"epoch": self.current_epoch},
exclude_zero_weights=True,
)
#########################################
segformer_finetuner = SegformerFinetuner(
model=model,
id2label=id2label,
train_table=train_table,
val_table=val_table,
test_table=test_table,
learning_rate=LEARNING_RATE,
)
Training the model¶
[ ]:
early_stop_callback = EarlyStopping(
monitor="val_loss",
patience=5,
verbose=True,
)
checkpoint_callback = ModelCheckpoint(save_top_k=1, monitor="val_loss", save_last=True)
trainer = pl.Trainer(
accelerator="cpu", # CPU avoids MPS tensor view issues with SegFormer
callbacks=[early_stop_callback, checkpoint_callback],
max_epochs=EPOCHS,
val_check_interval=1.0, # validate once per training epoch
log_every_n_steps=7,
)
trainer.fit(segformer_finetuner)
Checking results¶
[ ]:
res = trainer.test(ckpt_path="last")
[ ]:
%matplotlib inline
mapped_test_dataloader = segformer_finetuner.test_dataloader()
batch = next(iter(mapped_test_dataloader))
images, masks = batch["pixel_values"].to(device), batch["labels"].to(device)
segformer_finetuner.eval().to(device)
outputs = segformer_finetuner.model(images, masks, return_dict=True)
batch_prediction = image_processor.post_process_semantic_segmentation(outputs, batch["mask_size"].tolist())
n_rows = len(images)
n_cols = 3
fig_width = n_cols * 5
fig_height = n_rows * 5
fig, ax = plt.subplots(n_rows, n_cols, figsize=(fig_width, fig_height))
fig.suptitle("Test Batch Predictions", fontsize=16)
plt.tight_layout(pad=3.0, h_pad=-1.0, w_pad=1.0, rect=[0, 0, 1, 1])
for i in range(n_rows):
for j in range(3):
ax[i, j].axis("off")
ax[i, 0].imshow(masks[i, :, :].cpu().numpy(), cmap="gray")
ax[i, 0].set_title(f"Ground Truth (id={i})", fontsize=14)
ax[i, 1].imshow(batch_prediction[i].cpu().numpy(), cmap="gray")
ax[i, 1].set_title("Predicted mask (latest model)", fontsize=14)
im = tlc.active_run().metrics_tables[-1][i]["predicted_mask"]
ax[i, 2].imshow(np.array(im), cmap="gray")
ax[i, 2].set_title("Predicted mask (3LC metrics)", fontsize=14)