Add new data to dataset with splits¶
Add new data and re-split a dataset.
When adding new incoming data to a dataset that already has several split tables, let’s take a look at two ways to go about it:
Merge all the data into one table, and then create new splits from this table.
Create new split Tables for the incoming data and then join those with the corresponding existing tables.
Here we will show each of these in turn.
Install dependencies¶
[ ]:
INSTALL_DEPENDENCIES = True
[ ]:
if INSTALL_DEPENDENCIES:
%pip install -q 3lc
%pip install -q git+https://github.com/3lc-ai/3lc-examples.git
Imports¶
[ ]:
import tlc
from tlc_tools.split import split_table
Project setup¶
[ ]:
PROJECT_NAME = "3LC Tutorials - Splits"
1. Merge-first strategy¶
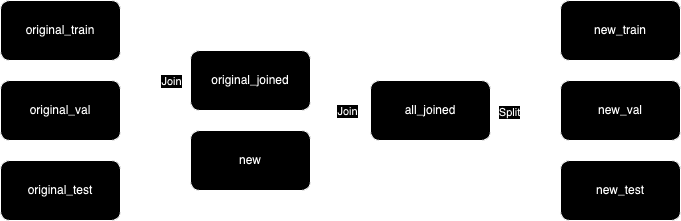
The merge-first strategy first merges in the new data, and then creates new splits for all the data.
[ ]:
DATASET_NAME = "add_new_data_merge_first"
[ ]:
original_train = tlc.Table.from_dict(
data={"my_column": [1, 2, 3, 4, 5]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_train",
)
original_val = tlc.Table.from_dict(
data={"my_column": [6, 7, 8, 9, 10]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_val",
)
original_test = tlc.Table.from_dict(
data={"my_column": [11, 12, 13, 14, 15]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_test",
)
[ ]:
original_joined = tlc.Table.join_tables(
tables=[original_train, original_val, original_test],
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_joined",
)
new = tlc.Table.from_dict(
data={"my_column": [16, 17, 18, 19, 20]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="new",
)
[ ]:
all_joined = tlc.Table.join_tables(
tables=[original_joined, new],
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="all_joined",
)
all_joined
Here a random split is applied, but any strategy could be used. See split-tables.ipynb for a more complete example.
[ ]:
new_tables = split_table(
all_joined,
splits={"train": 0.4, "val": 0.3, "test": 0.3},
)
new_train = new_tables["train"]
new_val = new_tables["val"]
new_test = new_tables["test"]
2. Split-first strategy¶
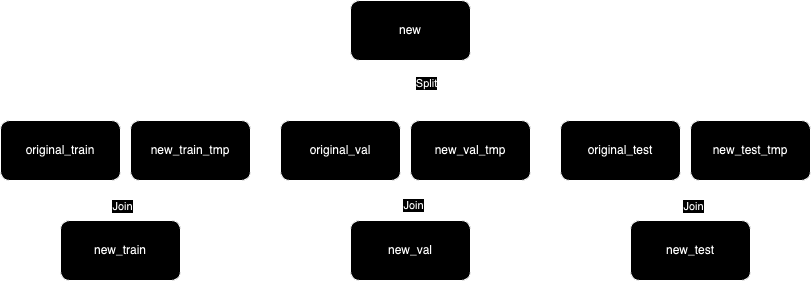
The split-first strategy first splits the new data, and then merges each resulting split with the corresponding original splits.
[ ]:
DATASET_NAME = "add_new_data_split_first"
[ ]:
original_train = tlc.Table.from_dict(
data={"my_column": [1, 2, 3, 4, 5]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_train",
)
original_val = tlc.Table.from_dict(
data={"my_column": [6, 7, 8, 9, 10]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_val",
)
original_test = tlc.Table.from_dict(
data={"my_column": [11, 12, 13, 14, 15]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="original_test",
)
new = tlc.Table.from_dict(
data={"my_column": [16, 17, 18, 19, 20]},
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="new",
)
Here a random split is applied, but any strategy could be used. See split-tables.ipynb for a more complete example.
[ ]:
new_tables_tmp = split_table(new, splits={"train": 0.4, "val": 0.3, "test": 0.3})
new_train_tmp = new_tables_tmp["train"]
new_val_tmp = new_tables_tmp["val"]
new_test_tmp = new_tables_tmp["test"]
[ ]:
new_train = tlc.Table.join_tables(
tables=[original_train, new_train_tmp],
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="new_train",
)
new_val = tlc.Table.join_tables(
tables=[original_val, new_val_tmp],
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="new_val",
)
new_test = tlc.Table.join_tables(
tables=[original_test, new_test_tmp],
project_name=PROJECT_NAME,
dataset_name=DATASET_NAME,
table_name="new_test",
)
[ ]:
[ ]: